


551. Flynn의 컴퓨터 시스템 분류 제안, 병렬처리와 분산처리 비교
- Flynn의 컴퓨터 시스템 분류 제안
- 컴퓨터의 명령어와 데이터의 흐름 개수에 따라 분류
- 종류 : SISD - 단일명령어 / 단일 데이터 흐름, SIMD - 단일명령어/다중 데이터 흐름, MISD - 다중명령어 / 단일 데이터 흐름. MIMD - 다중명령어 / 다중 데이터 흐름
- 병렬처리와 분산처리
- 병렬 처리

- 프로세서를 늘려 다수의 작업을 동시에 처리 : 프로세서 자체를 멀티코어로 병렬화 하거나, 여러 개의 프로세스를 이용하여 다수의 작업을 고속으로 처리 가능
- 구성 : 다수의 프로세서와 하나의 메모리로 구성
- 종류 : 벡터 계산이나 행렬 계산에 주로 사용되는 Array 프로세서나 백터 프로세서, 여러 개의 명령어를 동시 수행하는 파이프라인 기법 등
- 분산 처리

- 컴퓨터를 네트워크로 상호 연결하여 전체적인 일의 일부를 분산하여 처리
- 구성 : 다수의 프로세서와 메모리, 리소스로 구성
- 병렬 처리
552. 운영체제 유형별 특징
- 다중 프로그래밍 시스템

- CPU의 효율을 극대화하기 위해 여러 개의 프로그램이 마치 동시에 실행되는 것처럼 처리하는 방식
- 메모리 관리 필요
- 시분할 시스템

- 프로세서 스케줄링과 다중 프로그래밍을 사용해 각 사용자에게 컴퓨터를 시간적으로 분할 사용
- 분산처리 시스템

- 시스템마다 운영체제와 메모리를 가지고 독립적으로 운영되며 필요할 때 통신하는 시스템51. Flynn의 컴퓨터 시스템 분류 제안, 병렬처리와 분산처리 비교
- 다중처리 시스템
- 비대칭형 다중처리
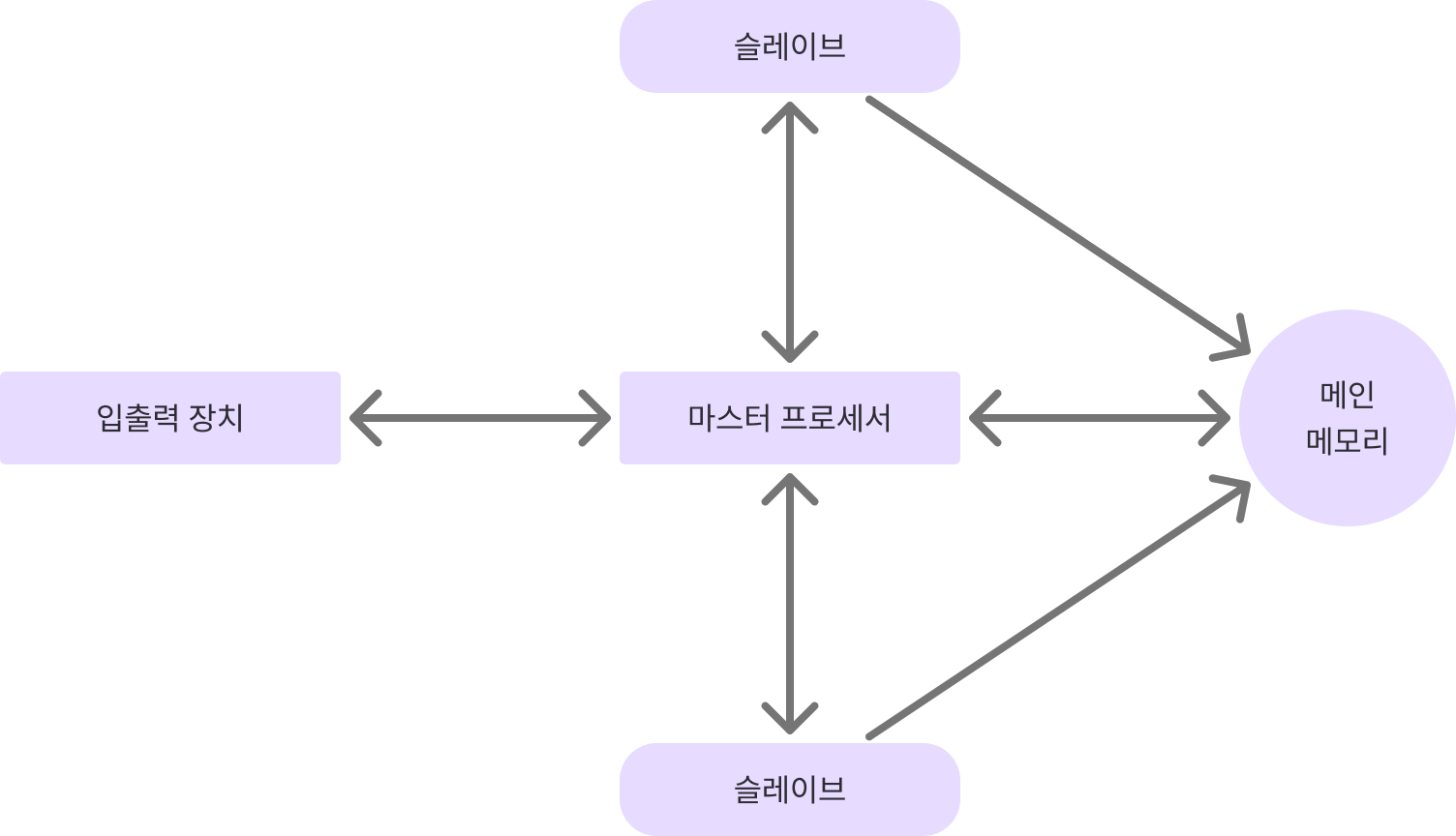
- 대칭형 다중처리

- 마이크로 프로세서 여러 개를 연결 해 다중 프로세서를 만듦
- 비대칭형 다중처리
- 일괄처리 시스템
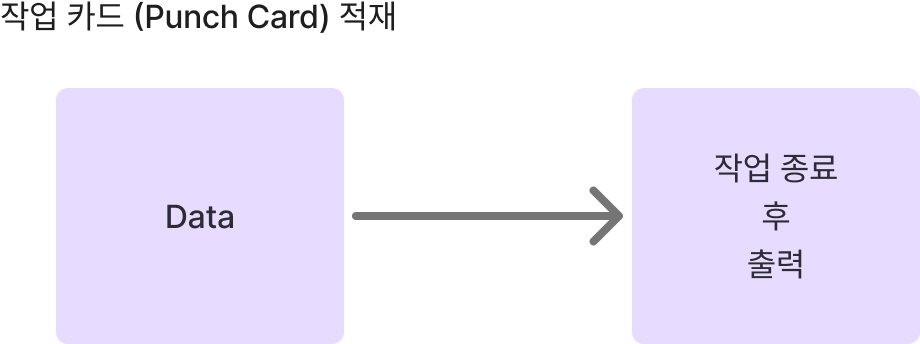
- 일정량의 데이터를 모아서 한꺼번에 일괄처리하는 방식
- 실시간처리 시스템
- 데이터에 대한 처리 요구 발생 시 즉시 처리 응답
- 시간 제한을 두고 수행하는 업무 적용
554. 프로세서 모델에 따른 분산 컴퓨팅 모델 분류
- 클라이언트 / 서버 모델
- 구성도
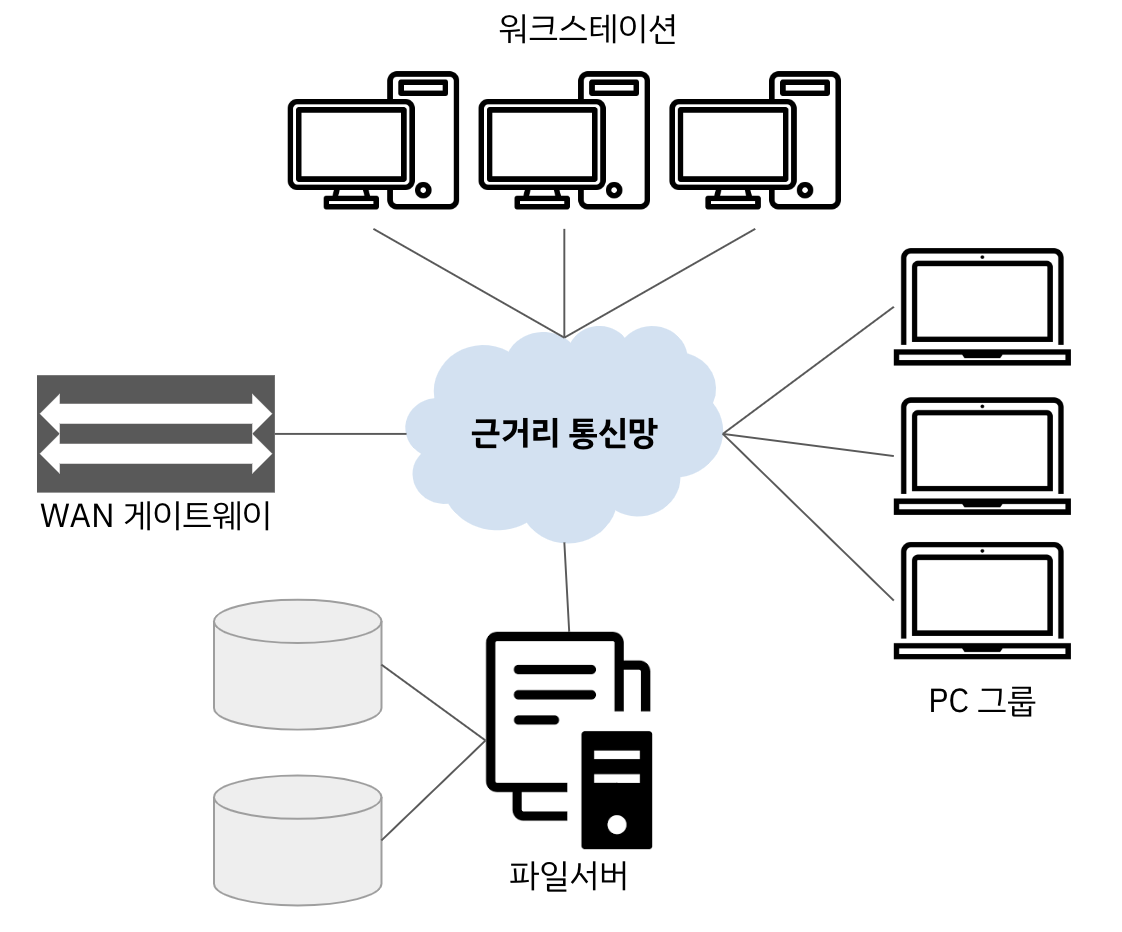
- 비대칭적 (Asymmetrical) 분산 시스템 구조
- 특징
- 대부분의 분산 시스템은 LAN을 기반으로 한 모델로 구성
- 다중 사용자 시스템으로 사용자들 간에 CPU를 공유
- 서버는 공유된 다양한 시스템 기능과 자원의 접근을 제공
- 구성도
- 프로세서 풀 모델
- 구성도

- 하나 이상의 프로세서 풀이 통합된 워크스테이션 - 서버 모델로 구성
- 특징
- 각 풀 프로세서는 서버가 연결되듯이 독립적으로 네트워크와 연결
- 풀에 있는 프로세서들은 단일 회로 보드로 구성
- 사용자 터미널은 단순히 시스템의 자원을 접근하는 수단을 제공
- 사용자의 작업은 부분 혹은 전체적으로 풀 프로세서 상에서 수행
- 사용자가 메인 태스크를 초기화하면, 풀 프로세서가 각 테스크에 할당되고 병렬로 수행
- 구성도
- 혼합 모델
- 구성도

- 앞의 두 모델을 혼합한 시스템
- 특징
- 사용자의 요구와 자원 처리가 매칭됨
- 병렬수행 : 여러 개의 풀 프로세서가 과부하 처리를 실행하기 위해 할당
- 사용자는 워크스테이션이나 터미널을 통하여 시스템에 접근
- 구성도
555. 위상에 따른 분산 컴퓨팅 구조 분류
- 위상에 따른 분산 컴퓨팅 구조 분류
- 완전 연결 구조 (Fully Connected)
- 토폴로지

- 각 노드가 시스템 내의 모든 다른 노트와 직접 연결
- 기본 비용은 노트 숫자의 제곱에 비례
- 토폴로지
- 부분 연결 구조 (Partially Connected)
- 토폴로지
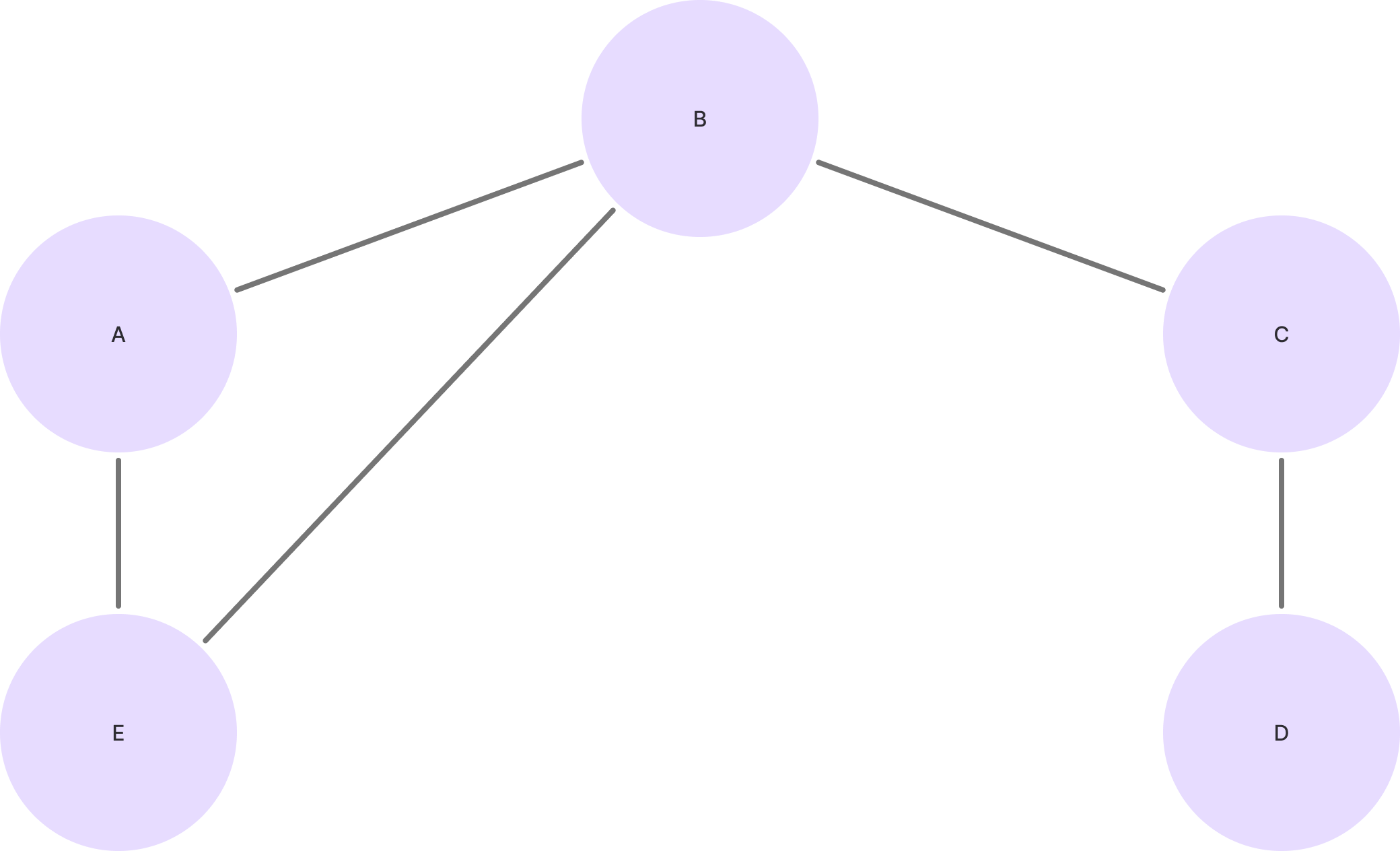
- 모든 노드 쌍에 대해서 직접 연결이 존재하는 형태가 아님
- 비용은 완전 연결 네트워크보다 낮음
- 통신 속도가 늦음
- 완전 연결 네트워크보다 신뢰성이 떨어짐
- 토폴로지
- 계층 구조 (Hierarchy)
- 토폴로지

- 각 사이트들은 트리 형태로 구성
- 형제 중의 하나가 다른 형제에게 메시지를 전달하려면 부모까지 올라가서 형제에게로 다시 내려감
- 토폴로지
- 성형 구조 (Start)
- 토폴로지

- 중심 노드는 타 노드와 연결, 타 노드는 상호간 연결되지 않는 방식
- 비용은 노드 수에 비례하나 일반적으로 통신비용은 낮음
- 중심 노드에서 병목 현상이 발생
- 토폴로지
- 환형 구조 (Ring)
- 토폴로지

- 단방향, 양방향 통신 방법 존재
- 단방향 : 노드는 한 방향으로만 정보 전달
- 양방향 : 양쪽 이웃 노드에게 정보 전달
- 기본 비용은 노드 수에 비례
- 단일 연결, 이중 연결 방식이 존재
- 토폴로지
- 다중 접근 버스 구조 (Multi-access Bus)
- 토폴로지
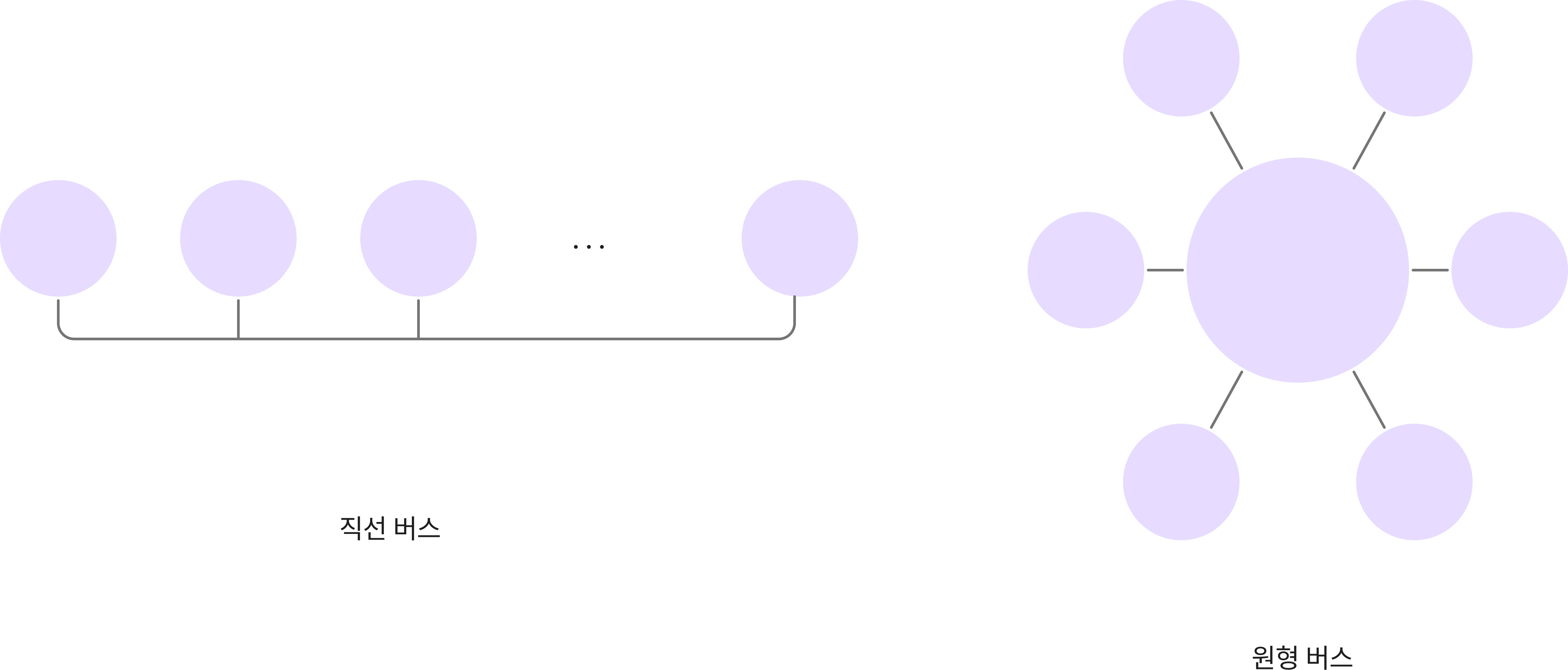
- 공유되는 하나의 버스가 존재
- 비용은 노드 수에 비례하며, 버스회선이 고장나면 네트워크가 분할됨
- 직선 버스, 환영 버스 유형이 존재
- 토폴로지
- 완전 연결 구조 (Fully Connected)
558. 페이징 기법과 세그먼테이션 기법
- 페이징 기법
- 가상기억장치 내의 프로그램과 데이터를 고정되게 분할한 용량(페이지)을 주기억장치에 사상시키는 기법
- 프로그램의 실제 주소와 주기억장치 주소가 다르므로 PMT 필요
- 외부단편화 해결 가능, 내부단편화 발생
- 세그먼테이션 기법
- 가상기억장치 내의 프로그램과 데이터를 각 세그먼트가 주기억장치에 적재될 때마다 필요한 서로 다른 크기의 세그먼트로 분할
- 매핑테이블 (세그먼트 번호 : 주소 + 크기) 유지
| 항목 | 페이징 | 세그먼테이션 |
| 할당단위 | 고정 | 가변 |
| 적재단위 | 프로그램 일부 적재 | 프로그램 전체 적재 |
| 장점 | •외부 단편화가 없음 •교체시간이 짧음 |
•코드, 데이터 공유가 용이 •내부단편화가 최소화 |
| 단점 | •Thrashing 문제 심각 •내부단편화 코드나 데이터 공유 논란 |
•외부단편화가 발생 •교체시간이 길어짐 •주기억장치가 커야함 |
559. 파일 편성
- 파일을 형성하고 있는 레코드를 기록매체 위에 어떻게 배치할지에 대한 파일 구조 방식
- 레코드의 식별, 검색, 저장, 기록매체 종류에 따라 편성 방법이 상이분산처리 비교
- 편성 방법
- 순차 편성 (SAF)
- 파일 내의 레코드가 물리적으로 연속해서 기록되는 방식
- 장점 : 간단하고 버퍼링용 이, 가변길이 레코드, 메모리 효율이 높음
- 단점 : 느리고 수정이 어려움
- 매체 : 테이프
- 직접 편성 (DF)
- 키를 지정하면 대응하는 레코드의 기록위치가 계산에 의해 구해지는 방식
- 장점 : 수정 용이, 빠른 속도
- 단점 : 주소계산 시간 필요
- 매체 : 디스크, 드럼
- 색인 순차 편성 (ISAM)
- 키의 순번으로 나열된 레코드를 넣어 두는 주데이터 영역과 레코드 소래를 키와 포인터로 표시한 색인 레코드를 넣어두는 색인 영역을 조합하는 방식
- 장점 : 파일수정 용이, 빠른 속도
- 단점 : 키가 필요하며 사전에 배열 필요
- 매체 : 메모리, 드럼
- 구분 편성 (Partitioned Organization)
- 파일을 편성하는 멤버명과 어드레스가 들어간 등록부와 데이터 영역으로 편성하는 방식
- 순차 편성 (SAF)
563. 가상 메모리
- 주기억장치 안의 프로그램 양이 많아질 때 사용하지 않는 프로그램을 보조기억장치 안의 특별한 영역으로 옮겨서, 그 보조기억장치 부분을 주기억장치처럼 사용할 수 있는 영역
- 당장 실행할 프로그램만 주기억장치로 이동
- 가상메모리 관리정책
- 할당 정책
- 각 프로세스에게 할당할 메모리 크기를 관리
- 실행 중 주 기억장치 할당량 변화 알고리즘
- 기법 : 고정할당 기법, 가변할당 기법
- 호출 정책
- 언제 어느 항목들을 보조기억장치에서 주기억장치에서 가져올 것인지 결정
- 기법 : 요구호출 기법, 예측호출 기법
- 배치 정책
- 프로그램의 한 블록을 주기억장치의 어디에 배치할 것인가 관리
- 기법 : First Fit, Best Fit, Worst Fit
- 교체 정책
- 주기억장치에 적재할 공간이 없을 경우, 무엇과 교체할 것인가에 대한 관리
- 기법 : FIFO, LRU, FRU, NUR
- 할당 정책
567. 페이지 교체 알고리즘 (캐시 교체 알고리즘)
- 무작위 페이지 교체
- 특별한 사용자에게 차이를 두지 않고 교체하는 기법
- 교체할 페이지를 무작위로 선정
- 오버헤드가 적은 기법
- 바로 뒤에 참조될 페이지도 교체 가능
- FIFO
- 메모리에 올라온지 가장 오래된 페이지를 교체
- FIFO 이상현상 (Anomaly) 발생
- FIFO 이상 현상 : FIFO 기법 하에 프로세스에 더 많은 페이지를 할당할 경우 더 많은 페이지 부재가 발생하는 현상
- 최적 페이지 교체 (Optimal Page)
- 앞으로 가장 오랫동안 사용되지 않을 페이지를 찾아서 교체
- FIFO 모순을 해결
- 최소 페이지 부재율을 가지나 구현이 비현실적
- LRU (Least Recently Used)
- 가장 오랫동안 사용되지 않을 페이지를 교체
- 호출시간을 기록해야 하는 오버헤드 발생하나 효율적임
- LFU (Least Frequently Used)
- 사용빈도 (참조된 횟수) 가 가장 적은 페이지를 교체하는 기법
- 구역성 문제가 발생
- NUR (Not Used Recently)
- 최근에 사용되지 않은 페이지를 교체하는 기법
- 참조비트, 변경비트 사용
- LRU 시간 오버헤드 해결
568. 페이지 교체 알고리즘 (캐시 교체 알고리즘)
- 무작위 페이지 교체
- 특별한 사용자에게 차이를 두지 않고 교체하는 기법
- 교체할 페이지를 무작위로 선정
- 오버헤드가 적은 기법
- 바로 뒤에 참조될 페이지도 교체 가능
- FIFO
- 메모리에 올라온지 가장 오래된 페이지를 교체
- FIFO 이상현상 (Anomaly) 발생
- FIFO 이상 현상 : FIFO 기법 하에 프로세스에 더 많은 페이지를 할당할 경우 더 많은 페이지 부재가 발생하는 현상
- 최적 페이지 교체 (Optimal Page)
- 앞으로 가장 오랫동안 사용되지 않을 페이지를 찾아서 교체
- FIFO 모순을 해결
- 최소 페이지 부재율을 가지나 구현이 비현실적
- LRU (Least Recently Used)
- 가장 오랫동안 사용되지 않을 페이지를 교체
- 호출시간을 기록해야 하는 오버헤드 발생하나 효율적임
- LFU (Least Frequently Used)
- 사용빈도 (참조된 횟수) 가 가장 적은 페이지를 교체하는 기법
- 구역성 문제가 발생
- NUR (Not Used Recently)
- 최근에 사용되지 않은 페이지를 교체하는 기법
- 참조비트, 변경비트 사용
- LRU 시간 오버헤드 해결
569. 가상 메모리 배치 정책
- 가상메모리 배치 정책
- 프로그램의 한 블록을 주기억장치의 어디에 배치할 것인가 관리
- 주요 배치 정책
- 최초 적합 (First Fit) : 프로그램, 데이터가 들어갈 수 있는 빈 영역의 첫 번째 분할 영역에 배치
- 최적 적합 (Best Fit) : 프로그램, 데이터가 들어갈 수 있는 빈 영역 중 단편화를 가장 적게 남기는 분할 영역에 배치
- 최악 적합 (Worst Fit) : 프로그램, 데이터가 들어갈 수 있는 빈 영역 중 가장 큰 영역에 배치
구분 First Fit Best Fit Worst Fit 설명 가장 처음에 남는 공간에 할당 스캔을 하여 최적의 공간에 할당 가장 큰 남은 공간에 할당 장점 효율성이 높음 최적의 공간에 할당 없음 단점 단편화 발생 Scanning 시간 소요 낭비 영역 발생 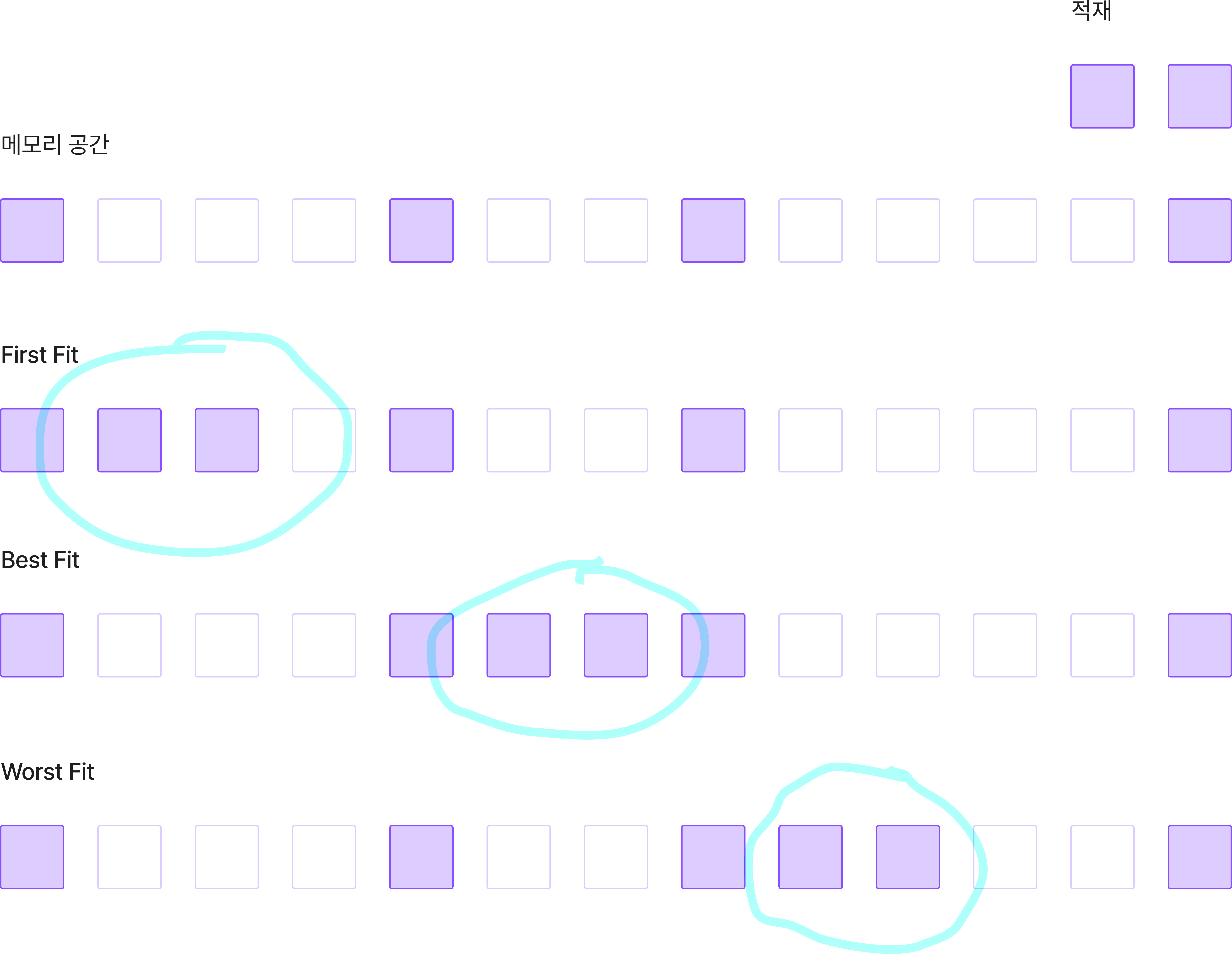
- 문제풀이
할당 영역 운영체제 1 50K 사용중 2 400K 사용중 3 200K
- 150k의 작업 요구 시, 위의 그림에서 1 영역은 50k로 배치가 불가능
- First Fit : 최초로 발견 가능한 적합한 크기 영역은 400k의 크기를 가진 2 영역
- Best Fit : 빈 영역 중 150k가장 근접한 크기 영역은 200k의 크기를 가진 3 영역
573. 하이퍼 큐브
- 다중처리기의 일종
- 다중처리기 : 하나의 시스템에 여러 개의 처리기를 두어 하나의 작업을 처리기에 나누어 할당하여 수행
- 처리기 : 각각의 기억장치를 가지고 있으며, 통신 채널에 의해 처리기를 모두 연결
- 10~1000대의 처리기를 병렬로 동작시키는 컴퓨터 구조로 소결합 다중 처리기라고도 함
- 기하학적 구조는 정육면체의 각 정점에 처리기가 있고, 변이 통신 회선으로 구성됨
- 예시
- 3차원 하이퍼 큐브 : 8개의 처리기를 가지고 있는데 각각 3회선 통신채널을 가지고 있음
- CPU 개수 = 8 * 8 * 8 = 512
577. 교착 상태의 해결 방안
- 예방 (Prevention)
- 상호배제, 점유와 대기, 비선점 및 환형 대기 조건의 부정
- 교착상태가 발생할 가능성을 완전히 배제하는 방법
- 회피 (Avoidance)
- Banker's Algorithm : 은행가 알고리즘
- Wait-die, wound-wait 알고리즘
- 발견 (Detection)
- 시스템의 상태를 감시 알고리즘을 통해 교착상태 검사
- 자원할당 그래프, Wait for Graph
- 회복 (Recovery)
- Deadlock이 없어질 때까지 프로세스를 순차적으로 Kill하여 제거
578. 세마포어
- 운영체계 또는 프로그램 작성 내에서 지원하는 상호배제 알고리즘
- 세마포어 변수 (S) 및 두 개의 연산 (P, V)으로 임계 영역에 접근하는 잠금 장치에 대한 이론적 기반
| Process | 알고리즘 | 상태값 |
| 초기화 | 세마포어에 하나의 대기큐를 할당하고 초기화 | S = 1 |
| P 연산 | P(S) 연산 : wait() 수행 While s = 0 do wait //대기 s = s- 1 //독점 |
S = 0, 자원할당 상태 |
| V 연산 | V(S) 연산 : Signal() 수행 s = s + 1 |
S = 1, 자원해제 상태 |
579. LRU 알고리즘
- 가장 오랫동안 사용되지 않을 페이지를 교체하는 알고리즘
- 문제 풀이
-
입력값 1 2 1 0 4 1 3 프레임1 1 1 1 프레임2 2 4 프레임3 0 3 - 페이지 참조 순서 : 1, 2, 1, 0, 4, 1, 3 인데 3개의 페이지 프레임을 가지고 있으므로
LRU (Least Recently Used) 알고리즘은 최근에 가장 최소로 참조한 페이지를 교체하므로
들어온 페이지 : 1, 2, 1, 0 miss 1, 2, 0 Hit : 1 (첫 번째 프레임의 1 hit)
1, 4, 3 Hit 1 (첫 번째 프레임의 1 hit)
miss 4 (가장 오래 전 참조한 두 번째 프레임과 교체)
miss 3 (가장 오래 전 참조한 세 번째 프레임과 교체)
따라서 페이지 대치의 최종 결과는 1, 4, 3
-
580. 파일 디스크립터
- 파일 기술자 (File Descriptor)의 개념
- 프로세스에서 특정 파일에 접근할 때 사용하는 추상적인 값 또는 자료 구조
- 일반적으로 0이 아닌 정수 값을 가지며, UNIX, Windows 등 시스템에 따라 구조가 상이
- 파일을 open(), create() 할 때, 커널이 필요한 동작 수행 후 파일 디스크립터 값을 리턴
- 파일 시스템의 개념
- 운영체제에서 보조기억장치와 그 안에 저장되는 파일을 관리하는 시스템의 통칭
- 각 OS에서 파일이나 자료를 쉽게 발견 및 접근할 수 있도록 보관 또는 조직하는 체계
- 보조 기억 장치에 저장된 각 파일과 그 구조
- 파일 시스템의 유형
- UNIX 파일시스템 : Boot, Super, Data block 및 List로 구성
- LINUX 파일시스템 : EXT2, EXT3, EXT4 등 다양한 구조로 존재
- WINDOWS 파일시스템 : FAT32, NTFS, ReFS 등의 파일시스템 구조 존재
583. 디렉토리
- 디렉토리는 파일 이름을 해당 디렉토리 항목으로 변환해주는 심볼 테이블
- UFD (User File Directory) 와 MFD (Master File Directory)
- UFD : 자신만의 사용자 파일 디렉토리
- MFD : 사용자의 이름이나 계정번호로 색인되어 있고, 각 엔트리는 사용자 UFD 지정
- 디렉토리의 종류
- Single-Level Directory
- 가장 간단한 구조
- 서로 다른 사용자도 같은 이름 이용 불가
- 파일의 갯수가 많아지면 성능 제약
- Two-Level Directory
- MFD와 UFD로 구성
- 사용자들에게 개별적인 디렉토리 생성
- 다른 계정일 경우 중복 이름 이용 가능
- 트리구조 디렉토리
- 2단꼐 디렉토리 확장
- 사용자들이 서브 디렉토리 구성 가능
- 트리구조는 하나의 루트 디렉토리를 가지며 모든 파일은 고유 경로를 가짐
- 파일은 절대 경로와 상대 경로 두 가지 경로명 지정 가능
- 비순환 그래프
- 사이클이 없는 그래프로 디렉토리들이 서브 디렉토리와 파일 공유 허용
- 파일 삭제 시, 대상이 없는 포인터를 남김
- 일반 그래프 디렉토리
- 디렉토리 무한루프 발생하지 않도록 파일을 하위 디렉토리가 아닌 링크만 허용
- 디렉토리 순회 시, 링크가 있으면 우회하여 순환 회피
- Single-Level Directory
587. 프로세스와 스레드
- 프로세스 : 파일 형태로 저장되어 관리되다가 실행을 시키면 동작, 이 때 실행 중인 프로그램
- 한 개의 프로세스 (또는 Task) 는 여러 개의 스레드로 나누어 수행될 수 있음
- 다중 프로그래밍 시스템에서 CPU를 받아서 수행되는 프로그램 단위
- 프로세스나 태스크보다 더 작은 단위
- 실행 환경을 공유시켜 기억장소의 낭비가 줄어듦
588. 프로세스와 스레드
- 프로세스 : 파일 형태로 저장되어 관리되다가 실행을 시키면 동작, 이 때 실행 중인 프로그램
- 한 개의 프로세스 (또는 Task) 는 여러 개의 스레드로 나누어 수행될 수 있음
- 다중 프로그래밍 시스템에서 CPU를 받아서 수행되는 프로그램 단위
- 프로세스나 태스크보다 더 작은 단위
- 실행 환경을 공유시켜 기억장소의 낭비가 줄어듦
589. CPU Scheduling
- 프로세스 작업 수행을 위해 언제, 어느 프로세스에 CPU를 할당할 것인지를 결정하는 작업
- 라운드 로빈 스케줄링 : 대화식 사용자를 위한 시분할 시스템 (Time Sharing System)을 위해 고안
- CPU 스케줄링 기법
| 구분 | 선점 (Preemptive) 스케줄링 | 비선점 (Non-preemptive) 스케줄링 |
| 개념 | 한 프로세스가 CPU를 차지하고 있을 때 우선 순위가 높은 다른 프로세스가 현재 프로세스를 중지시키고 자신이 CPU를 선점 높은 우선순위를 가진 프로세스들이 빠른 처리를 요구하는 시스템에 유용 |
한 프로세스가 CPU를 차지하고 있으면, 작업 종료 후 CPU 반환 시까지 다른 프로세스는 CPU 선점 불가 |
| 개념도 | if 우선 순위 P1 < P2 일 때, P2가 중간에 CPU 선점 가능 | if 우선 순위 P1 < P2 일 때, P2는 P1 종료 시까지 대기 |
| 장점 | 비교적 빠른 응답, 대화식 시분할 시스템에 적합 | 응답 시간 예상이 용이, 모든 프로세스에 대한 요구를 공정하게 처리 |
| 단점 | 높은 우선순위 프로세스들이 들어오는 경우 오버헤드를 초래 | 짧은 작업을 수행하는 프로세스가 긴 작업 종료 시까지 대기 |
| 기법 | RR, SRT, 다단계 큐, 다단계 피드백 큐 | FCFS, Priority, Deadline, SJF, HRN |
| 활용 | 실시간 응답환경, Deadline 응답 환경 | 처리시간 편차가 적은 특정 프로세스 환경 |
591. SJF
| 시간 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 서비스 | P1 (6) | P2 (3) | P3 (8) | P4 (7) | ||||||||||||||||||||
| CPU 점유 | P2 | P2 (3) | P2 | P1 | P1 | P1 | P1 | P1 | P1 | P4 | P4 | P4 | P4 | P4 | P4 | P4 | P3 | P3 | P3 | P3 | P3 | P3 | P3 | P3 |
- Shortest Job First
- 실행 시간이 가장 짧은 작업 순으로 CPU 수행하는 비선점 스케줄링 기법
- 문제 풀이
- 대기시간
- P1 = 3, P2 = 0, P3 = 16, P4 = 9
- 평균 대기시간 = (3 + 0 + 16 + 19) / 4 = 7
- 반환시간 (Turnaround Time)
- P1 = 3+ 6 = 9, P2 = 0 + 3 = 3, P3 = 16 + 8 = 24, P4 = 9 + 7 = 16
- 평균반환시간 = (9 + 3 + 24 + 16) / 4 = 13
- 대기시간
592. HRN
- SJF의 약점 보안 기법으로 실행 시간이 긴 프로세스를 차별하고 짧은 프로세스를 지나치게 선호하는 점을 보강한 알고리즘으로 각 프로세스의 우선순위를 서비스 시간만 아니고 서비스 대기시간도 계산하는 스케줄링 기법
- 우선 순위 계산식 : (대기시간 + 서비스 시간) / 서비스 시간
593. HRN
- SJF의 약점 보안 기법으로 실행 시간이 긴 프로세스를 차별하고 짧은 프로세스를 지나치게 선호하는 점을 보강한 알고리즘으로 각 프로세스의 우선순위를 서비스 시간만 아니고 서비스 대기시간도 계산하는 스케줄링 기법
- 우선 순위 계산식 : (대기시간 + 서비스 시간) / 서비스 시간
- 문제 풀이
- 작업 A : (5 + 20) / 20 = 1.25
- 작업 B : (40 + 20) / 20 = 3
- 작업 C : (15 + 45) / 45 = 1.3
- 작업 D : (20 + 20) / 20 = 2
594. SJF
- 실행 시간이 가장 짧은 작업 순으로 CPU 수행하는 비선점 스케줄링 기법
- 작업 2의 대기시간은 6 (7 - 1)
시간 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 작업 1 2 3 CPU 점유 1 1 1 1 1 1 1 2 2 2 3 3 3 3 3
- 대기시간
- 작업 1 = 0, 작업 2 = 6, 작업 3 = 8
- 평균 대기 시간 = ( 0 + 6 + 8 ) / 3
- 반환시간
- 작업 1 = 7 - 0 = 7, 작업 2 = 10 - 1 = 9, 작업 3 = 15 - 2 = 13
- 평균 반환 시간 = ( 7 + 9 + 13) / 3 = 9.67
- 대기시간
598. 동기화의 의미
- 동기식 전송
- 송수신기가 동일한 클록을 사용하여 데이터를 송수신
- 미리 정해진 수만큼 문자열을 한 묶음으로 만들어 일시에 전송하는 방법
- 파일 업로드, 파일 다운로드
- 수신 측에서 비트 계산을 해야 하고 문자를 조립하는데 별도의 기억장치가 필요
- 종류 : 비트지향 동기화 방법, 문자지향 동기화 방법
- 비동기식 전송
- 송수신기가 별도의 독립적인 클록을 사용하면서도 데이터를 송수신
- 한 번에 한 문자씩 전송함으로써 수신기가 새로운 무자의 시작점에서 재동기화
- START 비트와 STOP 비트 이용
- 패리티 비트를 통한 오류 검출
600. OSI 7계층의 의미 및 주요 프로토콜
- 응용 계층 (Application Layer)
- 사용자와 네트워크 간의 응용 서비스 연결, 데이터 생성
- 주요 프로토콜 : HTTP, TELNET, DHCP, DNS, FTP, SSH, SMTP, SNMP
- 단위 : Data
- 표현 계층 (Presentation Layer)
- 데이터의 형식 설정과 부호 교환, 암호화, 해독
- 주요 프로토콜 : MIME, TLS, SSL, JPEG, MPEG, SMB, AFP
- 단위 : Data
- 세션 계층 (Session Layer)
- 응용 프로세스 간의 연결 접속 및 동기 제어
- 주요 프로토콜 : SSH, TLS, RPC
- 단위 : Data
- 전송 계층(Transport Layer)
- 프로세스 간 논리적 통신 서비스 제공
- 패킷들의 전송 유효 확인, 실패한 패킷은 재전송하여 신뢰성 있는 통신 보장
- 오류검출과 복구, 흐름제어
- 주요 프로토콜 : TCP (3-Way Handshaking), UDP, SCTP, RTP
- 단위 : Segment
- 네트워크 계층 (Network Layer)
- 단말 간 시스템끼리 Data를 전송하기 위한 최선의 통신 경로 선택을 제공
- 주요 프로토콜 : IP, ARP, ICMP, IGMP, IPsec
- 단위 : Packet
- 데이터링크 계층 (Data Link Layer)
- 인접 시스템 간의 데이터 전송, 전송 오류 제어 (Frame)
- 오류 검출, 재전송, 흐름 제어
- 주요 프로토콜 : Ethernet, ATM, PPP
- 단위 : Frame
- 물리 계층 (Physical Layer)
- 통신회선으로 Data를 나타내는 '0'과 '1'비트의 정보를 회선에 내보내기 위한 전기적 변환이나 기계적 작업을 담당
- 주요 프로토콜 : RS-485, RS-232, X25/21
- 단위 : Bits
'자격증 > 정보처리기사' 카테고리의 다른 글
| [정보처리기사 필기] 기출문제 - 701 ~ 751. 오답노트 (0) | 2025.03.19 |
|---|---|
| [정보처리기사 필기] 기출문제 - 651 ~ 700. 오답노트 (0) | 2025.03.18 |
| [정보처리기사 필기] 기출문제 - 601 ~ 650. 오답노트 (0) | 2025.03.17 |
| [정보처리기사 실기] 정보처리기사 2020년 1회 실기문제 (0) | 2025.03.14 |
| [정보처리기사 필기] 기출문제 - 501 ~ 550. 오답노트 (0) | 2025.03.13 |