


251. 무방향 그래프의 특징
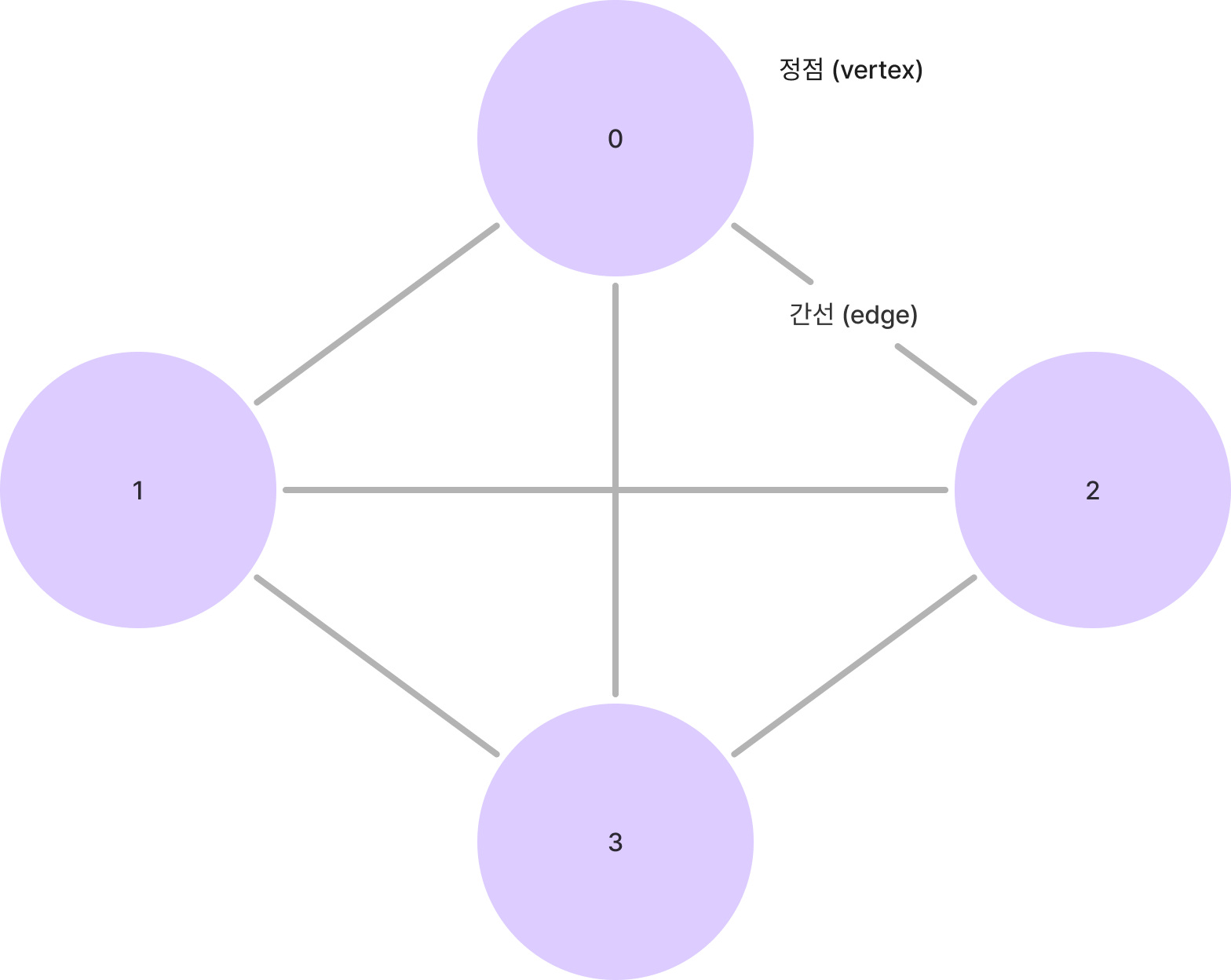
- 정점과 정점을 연결하는 간선에 방향성이 없는 그래프
- 최대 edge 수 : 정점(V)이 n개 있다면, 최대 간선 E = n (n-1)/2
254. 중위 표기법 -> 후위 표기법 변환
- 첫번째 계산 방법

- 연산 순서가 빠른 순으로 연산자를 그 연산을 수행하는 변수 뒤로 옮김
- 두번째 계산 방법

- 연산 우선순위에 따라 모든 연산에 괄호를 친 후 (괄호의 수 = 연산자의 수), 연산 우선순위의 순서로 연산자와 연산자 우측의 가장 가까운 닫힘 괄호를 교체하면서 괄호를 지워나감
255. 중위 표기법 -> 전위 표기법 변환
- 첫번째 계산 방법
- 연산 순서가 빠른 순으로 연산자를 그 연산을 수행하는 변수 뒤로 옮김
- 두번째 계산 방법

- 연산 우선순위에 따라 모두 괄호를 쳐 넣고, 연산 우선순위의 순서로 연산자와 연산자 좌측의 가장 가까운 열림 괄호를 교체하면서 괄호를 지워나감
256. Postix 연산
- 후위 연산을 중위 연산으로 변환하는 방법 : 앞에서부터 "변수", "변수", "연산자"순서로 된 부분을 찾아 연산자를 변수 사이로 옮기는 작업을 반복
- 작업이 된 부분은 변수로 취급, 혼란을 막기 위해 작업된 부분에 괄호 또는 박스를 쳐 놓으면 됨
| 순서 | 내용 | 진행 |
| 0 | 주어진 문제 | 3 4 * 5 6 * + |
| 1 | 3 4 가 "변수, 변수, 연산자" 순서 | ( 3 * 4 ) 5 6 * + |
| 2 | 5 6 * 가 "변수, 변수, 연산자" 순서 | ( 3 * 4 ) ( 5 * 6 ) + |
| 3 | (3 * 4) (5 * 5) + 가 "변수, 변수, 연산자" 순서 | ( 3 * 4 ) + ( 5 * 6 ) |
| 4 | 3 * 4 + 5 * 6 = 12 + 30 = 42 | |
257. 전위 표기식 연산
- Prefix 표기식을 Infix 표기식으로 변환해서 계산
- Prefix 표기식을 Infix 표기식으로 변환하기 위해서는 앞에서부터 "연산자", "변수", "변수" 순서로 된 부분을 찾아 연산자를 변수 사이로 옮기는 작업을 반복
| 순서 | 내용 | 진행 |
| 0 | 주어진 문제 | + - 5 4 x 4 7 |
| 1 | - 5 4가 "연산자, 변수, 변수" 순서 | + ( 5 - 4 ) x 4 7 |
| 2 | x 4 7 이 "연산자, 변수, 변수" 순서 | + ( 5 - 4 ) ( 4 x 7 ) |
| 3 | + ( 5 - 4 ) ( 4 x 7 ) 가 "연산자, 변수, 변수" 순서 | ( 5 - 4 ) + ( 4 x 7 ) |
| 4 | ( 5 - 4 ) + ( 4 x 7 ) = 1 + 28 = 29 | |
258. 전위 표기법 -> 후위 표기법 변환
- 전위식 → 중위식 : 전위 연산을 중위 연산으로 변환하기 위해서는 앞에서부터 "연산자, 연산자, 변수" 순서로 된 부분을 찾아, 연산자를 변수 사이로 옮기는 작업을 반복
- 중위식 → 후위식 : 연산 우선순위에 따라 연산자를 우측으로 보내면 됨
| 순서 | 변환 | 내용 | 진행 |
| 0 | 전위 > 중위로 변환 | 주어진 문제 | - / * A + B C D E |
| 1 | + B C 가 "연산자, 변수, 변수" 순서 | * A ( B + C ) D E | |
| 2 | * A ( B + C ) 가 "연산자, 변수, 변수" 순서 | ( A * ( B + C ) ) D E | |
| 3 | / ( A * ( B + C ) ) D 가 "연산자, 변수, 변수" 순서 | ( ( A * ( B + C ) ) / D ) E | |
| 4 | - ( A * ( B + C ) / D ) E 가 "연산자, 변수, 변수" 순서 | ( ( ( A * ( B + C ) ) / D ) - E ) | |
| 5 | 중위 > 후위로 변환 | ( B + C )가 가장 먼저 수행, + 를 C 뒤로 보내고 괄호를 지움 | ( ( ( A * B C + ) / D ) - E ) |
| 6 | A * B C + 가 그 다음 수행, * 를 + 뒤로 보냄 | ( ( A B C + * ) / D ) - E ) | |
| 7 | A B C + * / D 가 그 다음 수행, / 를 D 뒤로 보냄 | ( A B C + * D / - E ) | |
| 8 | A B C + * D / - E 가 마지막으로 수행, - 를 E 뒤로 보냄 | A B C + * D / E - |
259. 단위 모듈 구현 시 고려사항
- 단위모듈 구현 시 고려사항
- 응집도는 높이고, 결합도는 낮춤
- 공통모듈 구현을 먼저, 개별 단위 모듈 구현 시 이를 재사용
- 항상 예외처리 로직을 고려하여 구현
- 단위모듈 테스트 시 고려사항
- 단위모듈 구현이 완료되었으면 단위모듈 테스트를 함
- 단위모듈 테스트를 위해서 IDE 도구를 활용하여 단위모듈 하나하나에 대한 디버깅을 수행
- 단위모듈 테스트는 화이트박스 테스트 기법을 사용
263. 단위모듈 디버깅 자동화 도구
- 단위테스트 도구와 해당 언어는 첫 글자에 어느 정도 힌트가 있음
- 예외 사항
- C# : xUnit
- python : unittest
265. 단위모듈 테스트의 소스코드 커버리지
- 구문 커버리지 Statement Coverage
- 소스코드 구문에 대한 단순한 실행 여부 측정
- 아래 예제에서 조건문의 결과와 관계 없이 구문이 실행된 개수로서 계산
- 결정 커버리지 Decision Coverage
- 결정 조건 내의 전체 조건식이 최소한 참 / 거짓 한 번의 값을 가지도록 측정
- 조건 커버리지 Condition Coverage
- 전체 조건식의 결과와 관계 없이 각 개별 조건식이 참 / 거짓 한 번 모두 갖도록 개별 조건식을 조합
- 조건 / 결정 커버리지 Condition / Decision Coverage
- 전체 조건식이 참 / 거짓 한 번 씩 가지면서, 개별 조건식이 참 / 거짓 모두 한 번씩 갖도록 조합
- 변경조건 / 결정 커버리지 Modified Condition / Decision Coverage
- 각 개별 조건식이 다른 개별 조건식에 무관하게 전체 조건식의 결과에 영향
- 다중조건 커버리지 Multiple Condition Coverage
- 결정 조건 내의 모든 개별 조건식의 모든 가능한 논리적 조합 100% 보장
266. 빌드 자동화 도구 - 젠킨스
- 빌드 자동화 도구로서 가장 많이 활용되는 도구
- Java 기반의 오픈 소스로 지속적 통합관리 CI를 가능하게 함
- Apache-tomcat과 같은 서블릿 컨테이너 서버 기반으로 구동되는 시스템
- CVS, SVN, Git 등 다양한 버전관리 도구를 지원
- 젠킨스의 특징
- 쉬운 설치 : Jenkins, war 파일로 제공, "java -jar jenkins.war" 명령어로 설치 끝
- 친숙한 GUI : 웹기반 GUI를 통해 쉽게 전체적인 설정 변경이 가능, 잘못된 내용은 바로 체크하여 inline help를 제공
- 저장소 부하 감소 : 버전관리 도구에서 빌드에 사용될 목록만 따로 추출하여 변경 생성할 수 있는 기능을 제공, 전체 빌드로 인한 저장소 부하 감소 가능
- 실시간 피드백 : RSS 또는 e - mail 을 통해 실시간으로 빌드 실패 내역에 대해 담당자에게 통지 가능
- 분산 빌드 : 여러 대의 컴퓨터를 통해 분산 빌드나 테스트가 가능
- 3ʳᵈparty 플러그인 : 젠킨스는 타 도구의 통합을 지원, 데이터베이스와 개발도구와의 통합, 테스트 도구와의 통합
268. 테스트의 원칙 - 요르돈 법칙 / 눈덩이 효과
- 테스팅은 개발 초기에 시작해야 한다는 원칙 : 애플리케이션의 개발 초기 단계에 테스트를 계획하고 SDLC의 각 단계에 맞춰 전략적으로 접근하는 것을 고려
- 유사 : 하인리히 법칙 (1 : 29 : 300 의 법칙 - 대형사고가 발생하기 전에는 그와 관련된 수십차례의 경미한 사고와 수백 번의 징후들이 반드시 나타남)
269. V-모델의 V & V
| 검증 Verification | 확인 Validation |
| 개발자 관점에서의 시스템 검증 활동 개발하고 있는 시스템이 미리 정의한 사양에 부합하고 있는지를 검증 제품을 제대로 만들고 있느냐 검증 |
사용자 관점에서의 시스템 검증 활동 개발 완료 된 시스템이 사용자의 요구 사항을 충족하는지 확인 제품이 제대로 만들어 졌느냐 확인 |
271. 화이트박스 테스트
- 주로 개발 단계에서 수행
- Verification이 적합
- 인수테스트의 방식
- 모듈 내부의 조건, 루프구조 등 논리 구조, 제어구조를 검사
272. 블랙박스 테스트 기법
- Boundary Value Analysis : 등가 분할된 경계의 유효한 값과 경계에서 가장 가까운 유효하지 않는 값을 테스트 데이터로 선택하여 컴포넌트나 시스템을 테스트하는 기법
- Cause Effect Graphing Testing : 입력값을 원인으로 효과를 출력값으로 정하고 이에 따른 원인 결과 그래프를 만들어서 테스트 케이스를 작성하는 기법
- Equivalence Partitioning Testing : 입력값의 범위를 유사한 특징을 갖는 동등 그룹으로 나누고, 각 그룹마다 대표 값을 선정하여 테스트케이스를 선정하는 기법
- Comparison Testing : 동일 입력이 다른 버전에서도 동일한 결과를 출력하는지 검사
273. selection sort 정렬
- 선택정렬
- 루프를 돌면서 최소값을 왼쪽으로 보내는 정렬방식
| 단계 | 정렬상태 | 설명 |
| 초기값 | 8, 3, 4, 9, 7 | |
| PASS 1 | 3, 8, 4, 9, 7 | 8, 3 교환 |
| PASS 2 | 3, 4, 8, 9, 7 | 8, 4 교환 |
| PASS 3 | 3, 4, 7, 9, 8 | 8, 7 교환 |
| PASS 4 | 3, 4, 7, 8, 9 | 9, 8 교환 |
274. 퀵 정렬
- 피봇을 중심으로 데이터를 분할하고, 왼쪽은 작은 값 오른쪽은 큰 값으로 위치시키는 행위를 반복(재귀)하는 분할 정복 방식의 정렬
- 퀵 정렬의 분할원소는 어떤 것을 선택해도 됨
- 재귀를 사용하므로, 스택 공간을 사용해야 함
- 시간 복잡도 : O(Nlog₂N)
- 최악 : O(N^2)
275. 퀵 정렬
- 피봇을 중심으로 데이터를 분할하고, 왼쪽은 작은 값 오른쪽은 큰 값으로 위치시키는 행위를 반복(재귀)하는 분할 정복 방식의 정렬
- 퀵 정렬의 분할원소는 어떤 것을 선택해도 됨
- 재귀를 사용하므로, 스택 공간을 사용해야 함
- 시간 복잡도 : O(Nlog₂N)
- 최악 : O(N^2)
276. 합병 정렬
- Merge Sort
- 데이터를 분할한 후 병합하면서 정렬을 수행하는 정렬 알고리즘
- 존 폰 노이만이 개발한 정렬 방법
- 분할 정복 방식을 사용
- 분할 과정과 결합 과정의 두 부분으로 구성
- 시간복잡도는 평균 O(Nlog₂N)
277. 이진탐색
- 특징 : 비교횟수를 거듭할 때마다 검색 대상이 되는 데이터의 수가 절반으로 줄어듬
- 장점 : 시간복잡도 O(Nlog₂N)으로 빠르게 탐색할 수 있음
- 단점 : 검색할 데이터가 정렬되어 있어야 함
278. 이진트리
- 깊이가 n인 이진트리의 최대 노드의 수 : 2 ⁰ + (....) + 2 ⁽ⁿ⁻¹⁾
279. 인터페이스 보안 코딩
- 인터페이스 데이터 암호화를 해야할 땐 128 bit DES 알고리즘보다는 AES 알고리즘으로 함
- 암호화 기술 중 대칭키 알고리즘은 주로 AES, SEED 등이 많이 사용
- DES는 보안상 위험하다고 알려진 암호화 알고리즘
282. 검증검사 기법
- 테스트 레벨에 따른 테스트의 유형

- 단위 테스트 (단위 검사) : 구현된 단위 모듈 (함수, 서브루틴, 컴포넌트 등)의 기능 수행 여부를 판정하고 내부에 존재하는 논리적 오류를 검출
- 통합 테스트 (통합 검사) : 모듈 간의 인터페이스 연계를 검증하고 오류를 확인, 모듈 간의 상호 작용 및 연계 동작이 제대로 기능하는지 점검
- 시스템 테스트 (시스템 검사) : 단위, 통합 테스트 후 전체 시스템이 정상적으로 작동하는지 판정하는 기능을 점검
- 인수 테스트 (인수 검사) : 사용자 요구분석 명세서에 명시된 사항을 모두 충족하는지 판정하고 시스템이 예상대로 동작하고 있는지 점검
- 비공식적 인수테스트 : 사용자가 오류와 사용상의 문제점을 테스트하는 것
- 알파 테스트 (알파 검사) : 개발자의 장소에서 사용자가 개발자 앞에서 행해지며, 오류와 사용상의 문제점을 사용자와 개발자가 함께 확인하면서 검사하는 기법, 개발자 환경에서 테스트하는 기법
- 베타 테스트 (베타 검사) : 다수의 사용자를 제한되지 않은 환경에서 프로그램을 사용하게 하고 오류가 발견되면 개발자에게 통보하는 방식, 사용자 환경에서 테스트하는 기법
285. 블랙박스 검사 기법 유형
- 동등분할 기법, 동치 분할 검사 Equivalent Analysis : 입력값의 범위를 유사한 특징을 갖는 동등 그룹으로 나누고, 각 그룹마다 대표값을 선정하여 테스트케이스를 선정하는 기법
- 경계값 분석 기법 Boundary Value Analysis : 경계값 분석은 등가 분할된 경계의 유효한 값과 경계에서 가장 가까운 유효하지 않는 값을 테스트 데이터로 선택하여 컴포넌트나 시스템을 테스트하는 기법
- 원인 효과 그래프 기법 Cause Effect Graph : 입력값을 원인으로, 효과를 출력값으로 정하고 이에 따른 원인 결과 그래프를 만들어서 테스트 케이스를 작성하는 기법
- 결정트리 트리 Decision Tree : 입력값과 출력값을 트리형태로 만들어서 특정 입력값에 따라서 결정되는 출력값이 정해지도록 만든 테스트 작성 기법
286. 상향식 통합 검사
- 상향식 통합의 정의
- 애플리케이션 구조에서 최하위 레벨의 컴포넌트로부터 위쪽 방향으로 제어 경로를 따라 이동하면서 테스트를 시작
- 최하위 레벨의 컴포넌트들이 하위 컴포넌트의 기능을 수행하는 클러스터로 결합
- 상향식 통합 원리

- 상위 컴포넌트 개발이 수행하지 못한 경우 더미 컴포넌트인 드라이버를 작성해 각 통합된 클러스터 단위를 테스트 수행, 이후 테스트가 완료되면 각 클러스터들은 프로그램 위쪽으로 결합되며 드라이버는 실제 컴포넌트로 대체
287. 하향식 통합 검사
- 하향식 통합의 정의
- 메인 제어 컴포넌트부터 아래 방향으로 제어의 경로를 따라 이동하면서 하향식으로 통합하면서 테스트를 진행
- 메인 제어 컴포넌트는 작성된 프로그램을 사용, 아직 작성되지 않은 하위 제어 컴포넌트 및 모든 하위 컴포넌트를 대신하여 더미 컴포넌트인 스텁을 개발
- 하향식 통합 원리

- 깊이 - 우선 방식 또는 너비 - 우선 방식에 따라, 하위 컴포넌트인 스텁이 한 번에 하나씩 실제 컴포넌트로 대체됨
- 검사 초기에는 시스템의 구조를 사용자에게 보여줄 수 있음
289. 테스트 오라클
- 테스트 오라클의 개념 : 테스트의 결과가 참인지 거짓인지를 판단하기 위해서 사전에 정의된 참 값을 입력하여 비교하는 기법 및 활동을 말함
- 테스트 오라클의 유형
- 참 True 오라클 : 모든 입력 값에 대하여 기대하는 결과를 생성함으로써 발생된 오류를 모두 검출할 수 있는 오라클
- 샘플링 Sampling 오라클 : 특정한 몇 개의 입력 값에 대해서만 기대하는 결과를 제공해주는 오라클
- 휴리스틱 Heuristic 오라클 : 샘플링 오라클을 개선한 오라클, 특정 입력 값에 대해 올바른 결과를 제공, 나머지 값들에 대해서는 휴리스틱(추정)으로 처리하는 오라클
- 일관성 검사 오라클 : 애플리케이션 변경이 있을 때 수행 전과 후의 결과 값이 동일한지 확인하는 오라클
290. 테스트 설계 기법

- 구조기반 기법
- 소프트웨어나 시스템의 구조를 중심으로 테스트 케이스를 선정하여 테스트하는 기법
- 종류 : 기본 경로, 루프 검사, 제어 구문 검사, 데이터 흐름 검사 기법
- 명세기반 기법
- 테스트 케이스를 프로그램 명세서를 기반으로 테스트 케이스를 선정하여 테스트하는 기법
- 종류 : 동등 분할 기법, 경계값 분석, 결정 테이블 기법, 상태 전이 테스트, 유즈케이스 테스트, 페어와이즈 테스트, 직교 배열 테스트 기법
- 경험기반 기법
- 프로그램 명세서와 같은 산출물 없이 테스터의 경험을 기반으로 테스트 수행하는 기법
- 종류 : 탐색적 테스트, 즉흥적 테스트, 분류 트리기법
291. 소프트웨어 테스트
- 화이트박스 테스트 : 내부구조를 확인 - 루프 시험
- 블랙박스 테스트 : 외부 명세를 테스트
292. Plan-driven 소프트웨어 프로세스

- 순서
- Reguirements Specification
- Acceptance Test Plan
- System Specification
- System Integration Test Plan
- System Design
- Sub - System Integration Test Plan
- Detailed Design
- Module And Unit Code And Test
- Sub - System Integration Test
- System Integration Test
- Acceptance Test
- Service
293. 테스트 자동화 도구
- 설계 단계
- 명세 기반 테스트 설계 도구 : 소프트웨어 명세로부터 테스트 절차, 데이터, 드라이버 등 생성
- 코드 기반 테스트 설계 도구 : 소스 코드로부터 테스트 절차, 데이터, 드라이버 등 생성
- 테스트 관리 도구 : 테스트 계획수립, 프로세스 관리, 요구사항 및 결함 추적 관리
- 구현 / 테스트 단계
- 정적 분석 도구 : 프로그램을 수행하지 않고 분석하는 도구, 복잡도 측정 등을 수행
- 리뷰 및 인스펙션 도구 : 소스 코드 / 설계 문서를 분석하여 가이드 라인 및 규칙 준수 검사
- 커버리지 측정 도구 : 주어진 테스트 케이스에 의해 얼마나 테스트 되었는가를 측정
- 동적 분석 도구 : 프로그램이 수행되는 동안 이벤트의 상태를 파악하기 위하여 특정한 변수나 조건의 스냅샷을 생성 및 활용
- 성능 / 부하 / 시뮬레이션 도구 : 시스템 부하를 생성하고, 반응 시간 및 메모리 사용량 평가
- 기능 테스트 수행 도구 : 주어진 테스트 케이스 자동 수행, 예상 결과와 비교, 단위, 통합, 시스템, 인수의 모든 단계에서 수행
297. 삽입 정렬 기법
- 첫번째 key는 정렬된 것으로 간주하고, 두번째 key부터 순서에 맞는 위치에 삽입시켜 정렬하는 방법
298. 알고리즘 기법
- 분할과 정복 : 문제를 해결 가능한 부분 문제로 분할하고 부분 문제의 답을 기반으로 전체 문제 답을 해결, 부분 문제들은 서로 독립적인 관계
- 동적 계획법 : 입력 크기가 작은 부분 문제들을 모두 해결한 후에 그 해들을 이용하여 보다 큰 크기의 부분 문제들을 해결하여 최종적으로 원래 주어진 입력의 문제를 해결하는 알고리즘 (부분 문제들은 서로 의존적인 관계)
- 탐욕법 : 빠른 문제 해결을 위해 근사해 계산 기법 (최적해는 아님)
- 백트래킹 : 어떤 노드의 유망성을 점검하고 유망하지 않으면 그 노드의 부모 노드로 돌아간 후 다른 자손의 노드를 검색하는 알고리즘
299. selection sort 정렬
- n회전으로 표현하기에 적합한 정렬
- 선택정렬, 삽입정렬 : 앞쪽부터 작은 수로 채워짐 (초기상태 : 8 3 4 9 7)
- 선택정렬 : 3회전 - 3 4 7 9 8
- 삽입정렬 : 3회전 - 3 4 7 8 9
- 선택정렬, 삽입정렬 : 앞쪽부터 작은 수로 채워짐 (초기상태 : 8 3 4 9 7)
- n회전으로 표현하기에 적합하지 않은 정렬
- 퀵정렬 : 분할, 정복 방식, pivot 조건을 주어야 n 회전 으로 표현하기 적합
- 합정렬 : 이진트리를 통해 정렬
'자격증 > 정보처리기사' 카테고리의 다른 글
| [정보처리기사 필기] 기출문제 - 351 ~ 400. 오답노트 (0) | 2025.03.10 |
|---|---|
| [정보처리기사 필기] 기출문제 - 301 ~ 350. 오답노트 (1) | 2025.03.07 |
| [정보처리기사 필기] 기출문제 - 201 ~ 250. 오답노트 (1) | 2025.03.05 |
| [정보처리기사 필기] 기출문제 - 151 ~ 200. 오답노트 (2) | 2025.03.04 |
| [정보처리기사 필기] 기출문제 - 101 ~ 150. 오답노트 (3) | 2025.03.03 |