


352. 집계함수
- COUNT() : 튜플(행)이나 값들의 개수
- SUM() : 값들의 합
- AVG() : 값들의 평균값
- MAX() : 값들의 최대값
- MIN() : 값들의 최소값
- STDDEV() : 값들의 표준 편차값
- VARIANCE() : 값들의 분산값
353. BEETWEEN A AND B
- 특정 컬럼의 값이 A 이상 B 이하에 포함되는 데이터를 검색
- 수치 데이터, 날짜 데이터에 대해 범위 검색을 하고자 할 때 사용
354. SQL 부분범위 처리
- 조건을 만족하는 전체범위를 처리하는 것이 아니라 일단 운반단위까지만 처리하여 추출하는 처리 방식
- SQL 부분범위 처리 목적
- 스캔 범위를 나누어서 운반단위를 가능한 빨리 채워서 처리 속도를 향상
- 일부분만 처리하고서도 Optimizer의 특성을 이용하여 정확한 결과를 도출
- 처리 범위가 넓더라도 빠른 속도를 얻도록 하기 위함
- SQL 부분범위 처리 적용 원칙
- 부분범위처리의 자격
- 논리적으로 일부분만 처리한 결과가 전체범위를 읽어 추가적인 가공을 하지 않고도 처리한 결과와 동일하다면 자격이 있음
- 부분범위처리를 할 수 없는 경우
- Order By가 사용된 경우
- UNION, MINUS, INTERSECT 등 조회 후 추가 연산을 사용한 경우
- 부분범위처리를 할 수 없는 경우의 대체
- Order By : Index를 이용하여 Order by를 하지 않아도 되는 형태로 대체
- MINUS, INTERSECT : EXISTS, NOT EXISTS, IN, NOT IN 등으로 대체
- 부분범위처리의 자격
- SQL 부분범위 처리 방안
- SQL 구문에 Order By가 있는 경우 인덱스 등을 이용하여 Order By를 삭제하는 형태로 변환
- 결과 컬럼을 얻어올 때 인덱스에서 모두 가져올 수 있는 항목인지를 살펴서 인덱스가 다시 테이블을 읽지 않아도 되는 형태로 사용
- 보통 사용하는 MAX(seq) + 1 형태를 버리고 역순 인덱스를 이용하여 Next Seq (다음 시권스값)를 구하는 형태로 변경
- 데이터의 존재 여부를 체크하는 등의 로직을 수행해야 할 때, count()를 수행하는 것보다는 EXISTS를 이용하여 존재여부를 파악
- SQL 부분범위 처리 VS 전체범위 처리 비교
| 구분 | 전체범위처리 | 부분범위처리 |
| 특징 | 주어진 조건의 범위가 좁은 경우는 문제가 없으나 넓은 경우는 빠른 수행 속도를 기대하기 어려움 | 처리할 범위가 아무리 넓다고 하더라도 그 범위 중의 일부만 처리 |
| 스캔방법 | 드라이빙 조건을 만족하는 범위를 모두 스캔 | 드라이빙 조건을 만족하는 범위를 차례로 스캔함 |
| 체크조건 처리 방법 | 체크조건 검증 후 성공한 건에 대해 임시 저장공간에 저장 | 체크 조건을 검증하여 성공한 건을 바로 운반단위로 보냄 |
| 결과추출 방법 | 저장이 완료되면 필요한 2차 가공을 한 후 운반단위만큼 추출시키고 다음 요구가 있을 때까지 일단 멈춤 | 운반단위가 채워지면 수행을 멈추고 결과를 추출 |
357. DCL
- 데이터 제어어
- 데이터베이스의 규정이나 기법을 정의하고 제어하는 언어
- 사용자의 권한 부여/취소, 트랜잭션 제어
- 사용 명령어 : GRANT (권한 허가), REVOKE (권한 회수), COMMIT, ROLLBACK
- 갱신 권한 부여 SQL 문 : GRANT 권한 [컬럼 리스트] ON 객체 TO {사용자 | 역할 | PUBLIC}
| 기능 | 명령어 | 설명 |
| 무결성 | COMMIT | 수행된 결과를 실제 물리적 디스크로 저장 |
| ROLLBACK | 명령 수행 실패를 의미하며 수행된 결과를 원복시킴 | |
| SAVEPOINT (checkpoint) | 저장점 지정, 지정된 저장점부터 현재까지 일부만 ROLLBACK 가능 | |
| 데이터보안 | GRANT | 데이터베이스 사용자에게 사용 권한 부여 |
| REVOKE | 데이터베이스 사용자에게 부여된 사용 권한 취소 |
359. DDL
- 객체를 생성, 변경, 제거하기 위해 사용하는 명령어
- 명령 실행 후 기본적으로 Auto Commit (트랜잭션의 끝으로 간주) 됨
- CASCADE 옵션 사용 : 참조하는 테이블도 함께 삭제 - 해당 테이블만 삭제하고자 할 때는 CASCADE 옵션을 빼고 사용
| 구분 | 명령어 | 설명 |
| 생명 | CREATE | 데이터베이스 객체 생성 |
| 변경 | ALTER | 데이터베이스 객체 변경 |
| 삭제 | DROP | 데이터베이스 객체 삭제 |
| TRUNCATE | 데이터베이스 객체 내 튜플(행) 삭제 |
362. 트랜잭션의 특징 ACID
| 특성 | 설명 | 기법 |
| Atomicity 원자성 | • 분해할 수 없는 최소 단위 • 연산 전체가 성공 또는 실패 • 한 가지라도 실패할 경우 전체가 취소되어 무결성 보장 All or Nothing |
Commit / Rollback 트랜잭션 관리자 |
| Consistency 일관성 | 트랜잭션이 실행 성공 후 항상 모순 없이 일관성 있는 DB 상태 보존 | 참조 무결성 기법 (무결성 제어기) |
| Isolation 고립성 | 현재 수행 중인 트랜잭션이 완료될 때까지 트랜잭션이 생성한 중간 연산 결과에 다른 트랜잭션들이 접근할 수 없음을 의미 | • Serializable • Repeatable Read • Read Commit • Read Uncommit (병행 제어 관리자) |
| Durability 영속성 | 성공이 완료된 트랜잭션의 결과는 영구(속)적으로 데이터베이스에 저장됨 | 회복 기법 ( 연관회복 관리자) |
363. 트랜잭션 제어 언어 TCL 명령어
| 명령어 | 목적 | 설명 | 역할 |
| COMMIT | 거래내역 확인 | 하나의 논리적 단위에 대한 작업이 성공적으로 끝났고, 데이터베이스가 일관된 상태에 있을 때 트랜잭션이 수행한 갱신 연산이 완료된 것을 트랜잭션 관리자에게 알려주는 연산 | Atomicity 원자성 보장을 위한 명령어 |
| ROLLBACK | 거래내역 취소 | 하나의 트랜잭션 처리가 비정상 종료되어 데이터베이스의 일관성을 깨뜨렸을 때, 트랜잭션 일부가 정상 처리되었더라도 트랜잭션의 원자성을 구현하기 위해 이 트랜잭션이 수행한 모든 연산을 취소시키는 연산 | |
| SAVEPOINT (checkpoint) | 저장점 설정 | ROLLBACK할 위치 지정 |
364. 병행제어
- 동시성 제어, 다중 사용자 환경을 지원하는 데이터베이스 시스템에서 여러 트랜잭션이 성공적으로 동시에 실행될 수 있도록 지원하는 기능
- 병행제어의 목적
- 트랜잭션의 직렬성을 보장하고 동시 수행 트랜잭션 처리량 최대화
- 데이터베이스 시스템의 공유도 최대화
- 응답 시간 최소화
- 데이터의 무결성과 일관성을 보장
- 병행제어를 하지 않으면 발생하는 문제점
- 갱신내용 손실 Lost Update
- 오류 데이터 읽기 (현황파악 오류) Dirty Read
- 모순성 Inconsistency
- 연쇄 복귀 Cascading Rollback
- 회복 불능 Unrecoverability
365. 병행제어의 특성
- 병행 제어의 수행 목적
- 트랜잭션의 직렬성을 보장
- 동시 수행 트랜잭션 처리량 최대화
- 데이터베이스 시스템의 공유도 최대화
- 응답 시간 최소화데이터의 무결성과 일관성을 보장하기 위해 수행

- 트랜잭션 직렬성 충족 사례

- 직렬 스케쥴 A는 각 트랜잭션 T1, T2의 연산들을 각 소속 트랜잭션별로 모두 연속적으로 실행 (직렬스케쥴)
- 비직렬 스케쥴(B)는 각 트랜잭션 연산들을 병행으로 실행되지만 결과는 직렬스케쥴(A)와 동일 : 따라서 B는 병행 실행하더라도 결과가 직렬스케쥴과 동일한 직렬성을 보장
- 다중의 트랜잭션이 동시에 수행되는 다중 트랜잭션 환경에서 직렬성을 위배할 경우, 데이터 무결성이 훼손되는 문제점이 발생, 이를 해결하기 위해 동시성 제어 기법 필요
367. 동시성 제어를 수행하지 않은 경우 발생하는 문제점
- 갱신분실 Lost Update

- 먼저 실행된 트랜잭션 T1의 결과를 나중에 실행된 트랜잭션 T2이 덮어쓸 때 발생
- T2 Write(x) 연산으로 T1의 Write(x) 갱신무효화 문제 발생
- 정상적인 결과값은 x=400이어야 하나, T1의 Write(x) 연산의 손실로 x=200 오류값 발생
- 현황파악 오류 Dirty Read

- 트랜잭션 중간수행 결과를 다른 트랜잭션 T2이 참조 시 발생
- 100, 100원의 잔고가 있는 x, y 계좌에 2% 이자를 가산하여 합을 구함
- 트랜잭션 T1의 중간 수행 결과 (x=102, y-100)를 트랜잭션 T2가 참조하여 결과값 오류, 원래는 X=102, y=102를 참조해야 함
- 모순성 Inconsistency

- 복수 트랜잭션이 Data에 동시 접근 / 갱신으로 결과가 상호불일치, 모순 발생
- T1은 x,y에 100을 더하는 연산 수행, 최종 기대 값 (x=200, y=200), T2는 x,y에 3을 곱하는 연산 실시, 최종 기대 값 (x=300, y=300) -> 그러나 실제 최종결과 값 (x=600, y=400)으로 T1, T2 기대값과 불일치 (모순) 발생
- 연쇄복귀 Cascading Rollback

- 복수의 트랜잭션이 데이터 공유 시 특정 트랜잭션이 처리를 취소할 경우 관련된 다른 트랜잭션도 롤백을 해야 하나 불가능한 문제
- T1 롤백수행 시 T2도 연쇄 복귀되어야 하나 트랜잭션을 종료했기 때문에 복귀 불가
368. 병행제어의 로킹단위
- 로킹 : 데이터베이스 관리에서 하나의 트랜잭션에 사용되는 데이터를 다른 트랜잭션이 접근하지 못하게 하는 것
- 트랜잭션들을 갱신할 때는 반드시 로킹 Lock → 실행 Execute → 해제 Unlock의 규칙을 따라 실행
- 로킹 단위

- 병행 제어에서 한 번에 잠금할 수 있는 단위
- 데이터베이스, 테이블, 레코드, 필드 등에 사용
- 로킹 단위에 따른 관리성과 공유성
- 로킹 단위가 큼 : 로킹 수가 작음, 관리성 용이, 공유성 수준이 낮아짐
- 로킹 단위가 작음 : 로킹 수가 많음, 관리성 복잡, 공유성 수준이 높아짐
- 병행 제어 기법

- 2단계 잠금 기법 2 Phase Locking
- 확장 단계 : 트랜잭션에서 잠금만 수행
- 차단 단계 : 데이터 연산 SQL만 수행
- 수축 단계 : 트랜잭션에서 해제만 수
- 검증 기법 Validation
- 타임스탬프 순서 Timestamp Ordering
369. 병행제어의 로킹단위
- 로킹 : 데이터베이스 관리에서 하나의 트랜잭션에 사용되는 데이터를 다른 트랜잭션이 접근하지 못하게 하는 것
- 트랜잭션들을 갱신할 때는 반드시 로킹 Lock → 실행 Execute → 해제 Unlock의 규칙을 따라 실행
- 로킹 단위
- 병행 제어에서 한 번에 잠금할 수 있는 단위
- 데이터베이스, 테이블, 레코드, 필드 등에 사용
- 로킹 단위에 따른 관리성과 공유성
- 로킹 단위가 큼 : 로킹 수가 작음, 관리성 용이, 공유성 수준이 낮아짐
- 로킹 단위가 작음 : 로킹 수가 많음, 관리성 복잡, 공유성 수준이 높아짐
- 병행 제어 기법
- 2단계 잠금 기법 2 Phase Locking
- 확장 단계 : 트랜잭션에서 잠금만 수행
- 차단 단계 : 데이터 연산 SQL만 수행
- 수축 단계 : 트랜잭션에서 해제만 수
- 검증 기법 Validation
- 타임스탬프 순서 Timestamp Ordering
374. 데이터베이스 회복 요법
- 지연 갱신 Deferred Update
- 트랜잭션이 성공적으로 종료될 때까지 데이터베이스에 대한 실질적인 갱신을 연기하는 기법
- 즉시 갱신 Immediate Update
- 트랜잭션이 데이터를 변경하면 트랜잭션이 부분 완료되기 전이라도 즉시 실제 데이터베이스에 반영하는 기법
- 그림자 페이지 Shadow Paging
- 갱신 이전의 데이터베이스를 일정 크기의 페이지 단위로 구성하여 각 페이지마다 복사
- 본인 그림자 페이지로 별도 보관해 두고, 실제 페이지를 대상으로 트랜잭션에 대한 변경 작업을 수행하는 기법
- 검사점 Check Point
- 체크포인트 Checkpoing 회복 기법
- 회복 기법
- Undo 수행 : 검사점 이후 장애발생 이전에 완료된 경우
- Redo 수행 : 검사점 이후 장애발생 시점까지 완료하지 못한 경우
- 미디어 회복 Medaia Recovery
- 디스크 장애가 발생하면 가장 최근의 덤프 내용을 디스크에 적재하고 로그를 이용하여 가장 최근 덤프 이후 완료된 트랜잭션들에 대해 Redo 작업을 수행하여 회복하는 기법
- 데이터베이스 로그를 이용한 회복 기법
- [Trans - ID, start] 로그 레코드, [Trans - ID, commit] 로그 레코드가 모두 존재하는 트랜잭션들 : 재수행
- [Trans - ID, start] 로그 레코드는 로그에 존재하지만, [Trans - ID, commit] 로그 레코드가 존재하지 않는 트랜잭션들 : 취소하여 회복
376. REDO / UNDO
- 데이터 무결성을 보장하는 트랜잭션의 특징 중 Durability 영속성을 위해 필요한 중요한 요소
- REDO (Forward Recovery)
- 데이터베이스 내용 자체가 손상이 될 경우 가장 최근의 복제본을 적재 후 이후 일어난 변경만을 로그를 이용하여 재실행함으로써 데이터베이스 회복 기법의 구성요소
- Archive 사본 + Log 활용
- 파일 복사본과 로그를 이용한 전방향 회복 조치
- 완료된 트랜잭션의 장애에 대한 회복 조치로 트랜잭션의 영속성을 제공
- UNDO (Backward Recovery)
- 데이터베이스 내용 자체는 손상되지 않았지만 변경 중이거나 변경된 내용에 대한 신뢰성을 잃어버린 경우 모든 변경 내용을 취소하여 데이터베이스 회복 기법의 구성요소
- Log + Backward 취소 연산 수행
- 미완료 트랜잭션의 장애에 대한 회복 조치로 트랜잭션의 원자성 제공
378. 뷰 VIEW
- 하나 또는 복수의 테이블을 대체하는 가상 테이블로서 조작은 기본 테이블과 거의 동일하지만 삽입, 갱신, 삭제 연산에는 제약이 따름
- 테이블 A를 대체하기 위해 생성한 뷰 A는 신규 뷰 B를 생성 시 정의가 가능
- 뷰A 생성 : CREATE VIEW 뷰A AS select * from 테이블A;
- 뷰B 생성 : CREATE VIEW 뷰B AS select * from 테이블A a, 테이블B b where a.컬럼1 = b.컬럼1;
- 뷰가 정의된 기본 테이블이 삭제되면 뷰도 자동적으로 삭제
- 뷰는 물리적으로 구현되는 테이블이 아닌, 허용된 자료만을 제한적으로 보여주기 위해 하나 이상의 테이블로부터 유도된 이름을 가지는 가상 테이블
- 뷰의 특징
- 저장 장치 내 물리적으로 존재하지 않는 가상 테이블
- 데이터 보정 등 임시적인 작업을 위한 용도로 사용
- 기본 테이블과 같은 형태의 구조로 조작이 거의 비슷
- 삽입, 내용, 갱신에 제약
- 논리적 독립성 제공
- 독자적인 인덱스를 가질 수 없음
- Create를 이용하여 뷰를 생성
- 필요한 데이터만 골라 뷰를 이용하여 처리
379. 뷰에 대한 쿼리문
- CREATE VIEW 뷰A AS select * from 테이블A; : 테이블A의 모든 컬럼에 대해 뷰로 생성하는 SQL 명령어
- DROP VIEW 뷰A; : 뷰를 삭제 시에는 DELETE 명령어가 아닌 DROP 명령어를 사용하여 아래와 같이 삭제
- SELECT * FROM 뷰A; : 뷰A로 생성된 모든 컬럼에 대해 조회하는 SQL 구문
- CREATE VIEW 뷰A AS select * from 테이블A a, 테이블B b where a, 컬럼1=b, 컬럼1; : 테이블A, 테이블B를 조인 시 'where a.컬럼1=b.컬럼1' 조건을 만족하는 데이터만 뷰A로 생성하는 SQL 명령어
380. 인덱스
- 데이터를 빠르게 찾을 수 있는 수단
- 테이블에 대한 조회 속도를 높여주는 자료 구조로서 자동으로 생성은 되지 않으며 데이터 정의어 DDL의 명령어를 이용하여 생성, 변경, 삭제를 실행
- 데이터베이스의 성능향상을 위한 DB튜닝 기법으로 가장 많이 사용, 과다한 인덱스 사용은 DML의 성능이 떨어지며 불필요한 인덱스가 많아지면 DB에 차지되는 공간이 커짐
- PK(Primary Key) 컬럼은 PK를 생성할 때 자동으로 PK 인덱스가 생성됨, 인덱스가 생성되어 있다면 테이블의 일부분을 검색하여 데이터를 빠르게 출력
- 조건절에 '='로 비교되는 컬럼을 대상으로 인덱스를 생성하면 검색 대상 줄어들어 검색 속도를 높일 수 있으며, 경우의 수가 적은 일련번호, 주민등록번호 등 자주 빈번히 사용하는 컬럼을 대상으로 생성 시 검색 성능이 우수
382. 인덱스
- 인덱스 생성 구문 : CREATE [UNIQUE] INDEX <index_name> ON <table_name> (<column(s)>);
- 인덱스 설계서의 테이블명, 인덱스명, 컬럼명을 이용하여 인덱스 구문에 맞게 생성이 가능
- 인덱스 생성 시 데이터 타입은 고려되지 않음
- SQL의 유형
| 구분 | 설명 | 명령어 |
| 데이터 질의어 DQL | 데이터베이스에 저장된 데이터를 검색하는데 사용하는 질의어 | SELECT |
| 데이터 조작어 DML | 데이터베이스에 저장된 데이터를 수정, 삭제, 추가하는 명령어 | INSERT, UPDATE, DELETE |
| 데이터 정의어 DDL | 데이터베이스 객체를 생성하고 수정, 삭제하는 명령어 / 데이터베이스의 스키마를 정의, 스키마에 대한 명세는 시스템 카탈로그에 저장 | CREATE, ALTER, DROP |
| 데이터 제어어 DCL | 데이터베이스의 규정이나 기법을 정의하고 제어하는 언어 / 사용자 권한 부여, 취소, 트랜잭션 제어 | GRANT, REVOKE, COMMIT, ROLLBACK |
383. 해시함수
- 해싱 : 데이터의 신속한 검색을 위해 키 Key 값에 해시 함수를 적용하여 주소 값을 빠르게 계산하고 레코드가 저장된 위치를 직접 접근하는 방법
- 해시함수 관련 용어
- 버킷 Bucket : 동일한 해시 주소를 갖는 레코드(키와 주소쌍)들이 저장될 메모리 블록을 의미, 버킷의 크기에 따라 같은 해시 주소에 저장될 수 있는 레코드의 수가 결정
- 슬롯 Slot : 1개의 해시 레코드를 저장할 수 있는 공간을 의미, n개의 슬롯이 모여 하나의 버킷을 이룸
- 충돌 Collision : 해시 레코드를 삽입할 때 서로 다른 2개 이상의 데이터가 같은 해시 주소를 갖는 현상
- 동거자 Synonyms : 해시 함수가 같은 주소로 변환시키는 모든 레코드를 동거자라고 하며 충돌이 일어난 레코드들의 집합
- 오버플로우 Overflow : 계산된 해시 주소의 버킷 내에 저장할 공간이 없는 상태
384. 해싱함수의 종류
- 계수 분석 : 키 값을 구성하는 숫자의 분포를 파악하여 분포가 비교적 고른 자리부터 필요한 자리만큼 선택하여 레코드 주소를 결정하는 방법
- 제산법 : 키를 임의의 양의 정수로 나눈 나머지를 그 키의 레코드를 저장하는 주소로 결정하는 방법
- 중간 제곱법 : 키 값을 제곱한 값의 중간 부분 값을 선택하여 레코드 주소로 결정하는 방법
- 폴딩법 (중첩법)
- 키를 여러 부분으로 나누고, 나누어진 각 부분의 값을 모두 더하거나 보수를 취해 더하여 레코드 주소를 결정하는 방법
- 길이를 동일하게 여러 부분으로 나누고, 더하거나 XOR하여 주소 이동
- 기수 변환 : 주어진 키 값을 어떤 특정한 진법의 수로 간주하여 다른 진법으로 변환한 후 레코드 주소를 구하는 방법
- 숫자 분석 : 각 숫자의 분포를 이용해서 균등한 분포의 숫자를 선택해서 사용 방법
- 무작위 방법 : 난수를 발생, 탐색을 위한 해시의 경우 충돌이 발생하면 다음 난수를 이용하는 방법
385. 오버플로우
- 해싱에서 충돌이 일어난 자리는 계산된 해시 주소의 버킷 내에 저장할 공간이 없는 상태인 오버플로우가 발생했다는 의미
- 오버플로우의 해결방법
- 선형 개방 주소법

- 충돌이 발생한 다음 위치에서 차례로 검색하여 첫번째 빈공간에 저장
- 레코드 전체 개수를 미리 예측 가능할 경우 적용 가능한 방법
- 체인법

- 오버플로가 발생한 레코드를 별도의 버킷으로 연결하여 저장
- 링크를 위한 오버헤드 발생, 레코드 개수 예측하기 어려울 경우 적용
- 다중 해싱법 (확장 해싱)
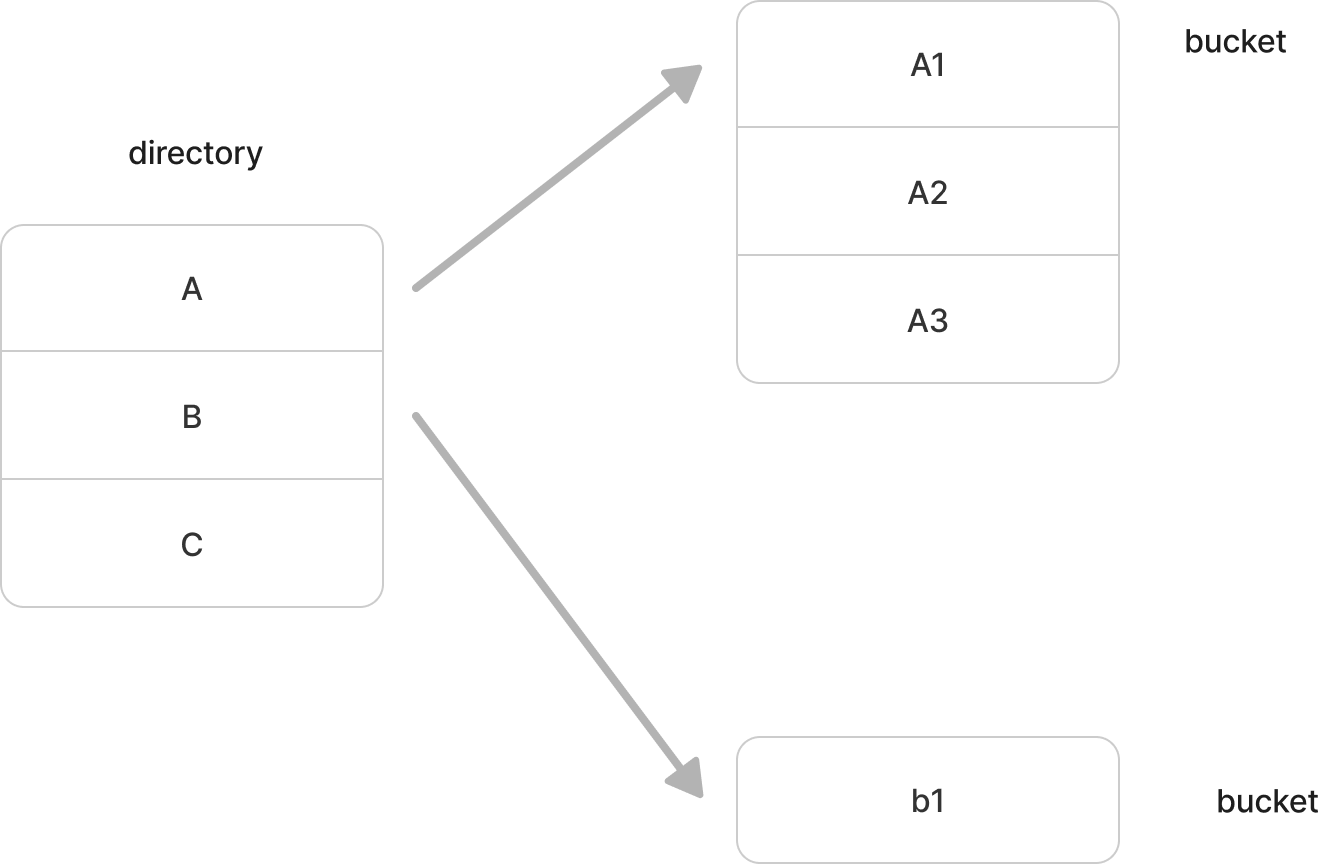
- 키 Key의 처음 비트를 이용하여 디렉토리를 통해 버킷에 접근할 수 있음
- 버킷에 오버플로가 발생할 경우 새로운 버킷을 생성하고 디렉토리의 포인터를 변경하거나 디렉토리를 확장
- 선형 개방 주소법
386. 집합 연산자
- 테이블을 집합 개념으로 보고, 두 테이블 연산에 집합 연산자를 사용하는 방식
- 여러 질의 결과를 연결하여 하나로 결합하는 방식을 사용
- 집합 연산자의 유형
- UNION : 여러 SQL문의 결과에 대한 합집합, 중복행 제거
- UNION ALL : 여러 SQL문의 결과에 대한 합집합, 중복행 제거하지 않음
- INTERSECTION : 여러 SQL문의 결과에 대한 교집합, 중복행 제거
- EXCEPT(MINUS) : 앞의 SQL문의 결과와 뒤의 SQL문의 결과 사이의 차집합, 중복행 제거, 일부 제품의 경우 MINUS 사용
- 집합 연산을 적용하려면 두 테이블이 합집합 호환성을 가져야 하며 참여하는 두 테이블의 컬럼의 개수와 데이터 타입이 일치해야 함
- 조인 : 두 개 이상의 테이블로부터 연관된 데이터를 결합해서 검색하는 방법
- 서브 쿼리는 다른 SQL문 안에 포함되어 사용된 또다른 SQL문
387. 조인
- 두 개 이상의 테이블로부터 연관된 데이터를 결합해서 검색하는 방법
- 두 테이블 사이에 속하는 컬럼 값들을 비교 연산자로 연결한 형태
- 조인 조건을 생략한 경우, 조인 조건을 잘못 작성하게 되면 카티션 프로덕트 연산이 수행되어 원하지 않은 결과를 얻게 됨
- 조인의 종류
- 논리적 조인
- 사용자의 SQL문에 표현되는 테이블 결합 방식
- 논리적 조인의 유형
- 내부조인 INNER JOIN
- 동등조인 EQUI JOIN : 특정 컬럼을 비교하여 같은 값을 추출 자연 조인 NATURAL JOIN
- 자연조인 NATURAL JOIN : 두 테이블의 모든 컬럼을 비교하여 같은 컬럼명을 가진 모든 컬럼값이 같은 경우를 추출
- 교차조인 CROSS JOIN : 조인 조건의 없는 모든 데이터의 조합을 추출
- 외부조인 OUTER JOIN
- 왼쪽 외부 조인 LEFT OUTER JOIN : 왼쪽 테이블의 모든 데이터와 오른쪽 테이블의 동일 데이터 추출
- 오른쪽 외부 조인 RIGHT OUTER JOIN : 오른쪽 테이블의 모든 데이터와 왼쪽 테이블의 동일 데이터를 추출
- 완전 외부 조인 FULL OUTER JOIN : 양쪽의 모든 데이터 추출
- 셀프조인 SELF JOIN : 한 테이블 내에서 조인 연산을 수행
- 내부조인 INNER JOIN
- 물리적 조인
- 데이터베이스 옵티마이저에 의해 내부적으로 발생하는 테이블 결합 방식
- Nested Loop Join, Merge Join, Hash Join
- 논리적 조인
390. SELECT 절
- SELECT 절에 그룹함수가 사용되면 그룹함수를 제외한 컬럼은 GROUP BY 절에 기술되어야 함
- SELECT count(*) FROM users; : USERS 테이블의 (NULL)값이 포함된 모든 행들의 총 개수를 반환하는 SQL 문장
- SELECT count(no), name FROM users group by name; : USERS 테이블의 NAME 컬럼을 그룹화하고 NO 컬럼 중 널 (NULL)값이 아닌 튜플(행)들의 개수를 반환하는 SQL 문장
- SELECT count(*) FROM users group by name; : USERS 테이블의 NAME 컬럼을 그룹화하고 널(NULL)값이 포함된 모든 튜플(행)들의 총 개수를 반환하는 SQL 문장
- SELECT count(no), name FROM users; : USER 테이블의 NAME 컬럼을 그룹화하기 위한 GROUP BY 절이 생략된 잘못된 SQL 문장
392. SQL 명령어
- HAVING
- 그룹제한조건 명령어
- 부서번호 DNO 컬럼값에 따른 그룹을 분류하고 집계함수 결과 값을 계산 후 Having 조건에 충족 여부를 검사 후 평균급여 2,500,000 이상인 부서를 출력
- WHERE : 특정 조건을 만족하는 튜플(행)을 검색하고자 할 때 사용
- ORDER BY
- 정렬 기준이 되는 컬럼과 정렬방법 명시
- 정렬방법의 종류
- ASC : 오름차순 정렬을 원할 경우 (기본값, 생략 가능)
- DESC : 내림차순 정렬을 원할 경우
- CUBE 그룹 함수
- 결합 가능한 모든 값에 대해 다차원 집계를 생성하는 함수
- 내부적으로 대상 컬럼의 순서를 변경하여 또 한번의 쿼리를 수행하고 총계는 양쪽 쿼리에서 모두 수행 후 한쪽에서 제거
- ROLLUP 그룹 함수
- 소계 등 중간 짐계값을 산출하기 위해 사용하며 컬럼의 수보다 하나 더 큰 레벨 만큼의 중간 집계값을 생성할 때 사용
396. 절차형 SQL의 기본 구성 요소
- SQL문의 연속적인 실행이나 조건에 따른 분기, 반복 등의 제어를 활용하여 다양한 기능을 수행하는 데이터베이스 저장 모듈로서 반복 또는 자주 수행하는 DB 작업을 효율적으로 수행할 수 있으며, 잘 정의된 절차형 SQL은 소프트웨어 개발 생산성이 향상
- 절차형 SQL 종류 (프로시저, 사용자 정의함수, 트리거)와 DBMS 벤더 (Oracle PL/SQL, SQL Sever T-SQL 등)마다 약간의 차이가 있음
- 절차형 SQL의 기본 구성요소
- DECLARE : 대상이 되는 프로시저, 사용자 정의함수 등을 정의
- BEGIN : 프로시저, 사용자 정의함수가 실행되는 시작점
- END : 프로시저, 사용자 정의함수가 실행되는 종료점
397. Oracle PL/SQL 문법
- 파라미터를 정의할 때, 괄호로 묶어주며, 파라미터 정의 후 RETURN 문장과 RETURN 값은 데이터 타입을 정의하고 FUNCTION BODY는 BEGIN~END 문장으로 묶어줌

398. 사용자 정의함수의 문법
- BEGIN, END : FUNCTION BODY에 사용
- RETURN : 결과값 리턴을 위해 사용
- GOTO : 절차형 SQL 제어문의 순차제어에서 사용하며, 제어가 건너 뛰는 곳을 지정하는 레이블과 함께 쓰임
400. Oracle PL/SQL 문법
- 프로시저 실행 시 EXEC 또는 EXECUTE 모두 사용이 가능

'자격증 > 정보처리기사' 카테고리의 다른 글
| [정보처리기사 필기] 기출문제 - 451 ~ 500. 오답노트 (0) | 2025.03.12 |
|---|---|
| [정보처리기사 필기] 기출문제 - 401 ~ 450. 오답노트 (2) | 2025.03.11 |
| [정보처리기사 필기] 기출문제 - 301 ~ 350. 오답노트 (1) | 2025.03.07 |
| [정보처리기사 필기] 기출문제 - 251 ~ 300. 오답노트 (0) | 2025.03.06 |
| [정보처리기사 필기] 기출문제 - 201 ~ 250. 오답노트 (1) | 2025.03.05 |