


451. 단일 테이블 클러스터링, 다중 테이블 클러스터링
- 단일 테이블 클러스터링
- 하나의 테이블에서 특정 칼럼을 클러스터 키로 생성하여 액세스의 효율성을 높임 : 동일한 값을 같은 장소에 저장
- 지정된 클러스터에 하나의 테이블만 생성
- 클러스터 인덱스를 경유하여 여러 건의 테이블 로우를 한 번의 스캔을 통하여 액세스하므로 랜덤 액세스 건수가 크게 줄어듦
- 다중 테이블 클러스터링
- 하나의 단위 클러스터에 여러 개의 테이블을 생성
- 기준되는 컬럼의 값이 동일한 각각 테이블의 로우들이 하나의 단위 클러스터에 저장되므로 기준 컬럼값으로 관련 테이블을 조인할 경우 추가적인 각 테이블들의 로우들이 흩어져 저장되는 경우에 발생하는 추가적인 액세스가 불필요하여 높은 성능의 조인이 가능
453. 테이블 크기 산정
- 한 Row 저장에 필요한 공간, 한 블록의 데이터 공간, 한 블록에 들어갈 수 있는 Row 개수, 총 데이터 Row 개수를 차례로 구하면서 필요한 총 데이터 공간을 산정
- 한 Row 저장에 필요한 공간
- Row Directroy + Row Header + Row의 데이터 길이 + )1 * <250bytes 이하 컬럼개수>) + (3 * <250bytes 초과 컬럼개수>)
- 한 블록의 데이터 공간
- (Block Size • Block Header • ITL 공간) * (100 • PCTFREEE)/100
- 한 블록에 들어갈 수 있는 Row 개수
- Data Space per Block (한 블록의 데이터 공간) / Row Space (한 Row의 저장에 필요한 공간)
- 총 데이터 Row 개수
- <초기 예상 건수> + <월중 예상 추가 건수> * (<데이터 보관 월 수> + 1)
- 필요한 총 데이터 공간
- Block Size * Total Row Size (총 데이터 Row 개수) / Row Size per Block (한 블록에 들어갈 수 있는 Row 개수)
454. 데이터 지역화
- 데이터베이스의 저장 데이터를 효율적으로 이용할 수 있도록 저장하는 방법
- 물리적 데이터베이스 설계
- 데이터 지역화를 고려한 보조 기억 장치의 설계는 중요함으로 물리적 데이터베이스 설계, 보조 기억 장치의 역할, 디스크상의 파일의 배치를 지역화 관점에서 검토를 수행
- 물리적 데이터베이스 설계의 고려사항
- 논리적인 설계의 데이터 구조를 보조 기억 장치상의 파일 (물리적인 데이터 모델)로 사상
- 하나의 파일에 여러 릴레이션이 저장될 수 있음
- 예상 빈도를 포함하여 데이터베이스 질의와 트랜잭션들을 분석
- 데이터에 대한 효율적인 접근을 제공하기 위하여 저장 구조와 접근 방법들을 다룸
- 질의를 효율적으로 지원하기 위해 인덱스 구조를 적절히 사용
458. 속성의 유형
- 정보를 나타내는 최소의 단위
- 엔티티의 성질, 분류, 수량, 상태, 특성 등을 나타내는 세부 항목
- 속성의 유형
- 기본 속성 : 해당 엔티티가 원래 가지고 있는 속성
- 설계 속성
- 원래 업무에는 존재하지 않지만 시스템의 효율성을 위해 임의로 추가되는 속성
- 예시 : 코드, 일련번호
- 파생 속성
- 다른 속성으로부터 계산이나 변형되어 생성되는 속성
- 데이터 중복성 및 무결성 확보를 위해 가급적 적게 정의 : 트리거 이용, 계산된 컬럼 Computed Column 선언
461. 물리 모델링 변환 과정 중 슈퍼 타입 기준 엔티티 통합, 서브 타입 기준 엔티티 통합
- 슈퍼 타입 기준 엔티티 통합
- 슈퍼 타입 엔티티를 중심으로 통합
- 서브 타입 엔티티와 단일 테이블로 통합
- 단일 테이블 통합으로 유리한 경우
- 데이터의 액세스가 상대적으로 용이, 수행 속도가 좋아지는 경우가 많음
- 뷰를 이용하여 각각의 서브 타입만을 액세스하거나 수정
- 서브 타입 구분이 없는 임의 집합에 대한 가공이 용이
- 단일 테이블 통합으로 불리한 경우
- 특정 서브 타입에 대한 Not Null 제한이 어려움
- 테이블의 컬럼 및 블록 수가 증가
- 처리마다 서브 타입에 대한 구분이 필요한 경우가 많이 발생
- 단일 테이블 통합으로 유리한 경우
- 서브 타입 기준 엔티티 통합
- 슈퍼 타입 속성들을 각각의 서브 타입에 추가하여 서브 타입마다 하나의 테이블로 변환
- 복수의 테이블로 분할이 유리한 경우
- 각 서브 타입 속성들의 선택 사양이 명확한 경우에 유리
- 서브 타입 유형에 대한 구분을 처리 마다할 필요가 없음
- 전체 테이블을 스캔하는 경우 유리
- 복수의 테이블로 분할이 불리한 경우
- 서브 타입 구분 없이 데이터를 처리하는 경우에 UNION이 발생
- 처리 속도 감소가 발생할 가능성이 높음
- 트랜잭션을 처리하는 경우 다수 테이블을 처리하는 경우가 자주 발생
- 복수의 테이블로 분할이 유리한 경우
- 슈퍼 타입 속성들을 각각의 서브 타입에 추가하여 서브 타입마다 하나의 테이블로 변환
462. 반정규화
- 정규화된 엔티티, 속성, 관계를 시스템의 성능 향상, 개발과 운영을 단순화하기 위해 데이터 모델을 통합하는 프로세스
- 데이터의 적합성과 데이터의 무결성을 우선으로 할 지 데이터베이스 구성의 단순화와 성능을 우선으로 할지를 결정
- 반정규화 수행절차
- 반정규화(역정규화) 대상 조사
- 범위 처리 빈도수 조사 : 자주 사용되는 테이블에 접근하는 프로세스 수가 많고, 항상 일정한 범위만 조회하는 경우
- 대량의 범위 처리 조사 : 대량의 데이터 범위를 자주 처리하는 경우
- 통계성 프로세스 조사 : 별도의 통계 테이블 고려
- 테이블 조인 개수 : 지나치게 많은 조인이 걸려 데이터 조회 작업이 어려운 경우
- 다른 방법 유도 검토
- 뷰 테이블 사용 : 지나치게 많은 조인이 걸려 데이터 조회 작업이 어려운 경우
- 클러스터링 또는 인덱스 적용 : 대량의 데이터는 PK의 성격에 따라 부분적인 테이블로 분리 (파티셔닝 기법)
- 어플리케이션 수정 : 로직을 번경함으로써 성능을 향상
- 반정규화(역정규화) 적용
- 테이블 반정규화
- 속성의 반정규화
- 관계의 반정규화
- 반정규화(역정규화) 대상 조사
464. 테이블 반정규화, 테이블 분할 기법
- 테이블 분할 기법
- 수직 분할 기법 : 특정 속성들만 접근이 잦을 경우 컬럼을 쪼개서 테이블을 만들어 사용하는 기법
- 수평 분할 기법 : 스키마는 동일하지만, 그 데이터 값을 이용하는 방법이 row별로 구분 지어지는 경우 (연도별 이력 조회 등)에 사용하는 기법
- 테이블 반정규화
- 중복테이블 추가 : 다른 업무이거나 서버가 다른 경우 동일한 테이블 구조를 중복하여 원격 조인을 제거하여 성능 향상
- 통계테이블 추가 : SUM, AVG 등을 미리 수행하여 자동 계산해둠으로써 조회 시 성능 향상
- 이력테이블 추가 : 마스터 테이블에 존재하는 레코드를 중복하여 이력테이블에 존재하는 방법
- 부분테이블 추가 : 하나의 테이블의 전체의 컬럼 중 자주 이용하는 집중화된 컬럼들이 있을 때 디스크 I/O를 줄이기 위해 해당 컬럼들을 모아놓은 별도의 반정규화된 테이블
471. 초기 데이터 구축
- 단시일에 대량의 데이터를 전환함에 있어 발생할 수 있는 위험을 최소화하고 신속하고 안정적인 이행 작업을 수행하기 위해 원천 시스템에서 특정 데이터들을 사전에 추출 및 변환해서 적재할 수 있도록 데이터베이스 혹은 데이터 파일로 구축해 두는 과정
- 기존 운영 시스템에 대한 이해를 바탕으로 구축 범위를 명확하게 식별해야 하며, 초기 데이터 구축 시 발생할 수 있는 예상 문제점을 도출하여 사전에 대응 방안을 마련
- 초기 데이터 구축 절차 : 구축 전략 수립 → 구축 대상 파악 → 구축 범위 확정 → 세부 고려사항 도출
- 초기 데이터 구축을 통한 기대효과
- 데이터 이관 시 업무 중단을 최소화, 안정성을 확보할 수 있는 방안 마련
- 데이터 이관 정합성 검증 방안과 오류 데이터에 대한 정비 방안 마련
- 데이터 이관 완료 후 데이터의 품질 검증 (전후 비교) 방안 마련
- 암호화된 개인정보에 대한 처리 방안 마련
472. ETL
- 다양한 소스 시스템으로부터 필요한 데이터를 추출하여 변환 작업을 거쳐 타겟 시스템으로 전송 및 로딩하는 모든 과정
- ETL의 변환 작업
- 특수한 엔진에서 진행
- 종종 변환 중인 데이터가 준비 테이블에서 임시로 보유되었다가 대상에 로드
- 일반적으로 발생하는 데이터 변환에는 필터링, 정렬, 집계, 데이터 조인, 데이터 정리, 중복 제거 및 데이터 유효성 검사 등의 작업이 포함
- ETL 프로세스별 방법
- 추출 E : JDBC, ODBC 기술의 이용, Flat File 생성, CDC 등
- 변형 T : 재구성, 정제(중복 제거, 일관성 확보), 변환(target repository에 적합한 형태), 데이터필드 검사, Rule 적용(전체 작업의 80% 소요)
- 적재 L : DBMS 고유 기능 / Utility (append, delete / insert, update) 이용
473. 색인 순차 파일
- ISAM : Index Sequential Access Method
- 순차 처리와 랜덤 처리가 모두 가능하도록 레코들을 키 값 순으로 정렬 (Sort) 시켜 기록
- 레코드의 키 항목만을 모은 색인을 구성하여 편성하는 방식
- 색인을 이용한 순차적인 접근 방법을 제공
- 레코드를 참조할 때 색인을 탐색한 후 색인이 가리키는 포인터(주소)를 사용하여 직접 참조
- 일반적으로 자기 디스크에 많이 사용되며, 자기 테이프에서는 사용할 수 없음
- 색인 순차 파일의 장단점
- 장점
- 순차 처리와 랜덤 처리가 모두 가능, 목적에 따라 융통성 있게 처리 가능
- 효율적인 검색이 가능하고 레코드의 삽입, 삭제, 갱신이 용이
- 단점
- 색인 구역과 오버플로우 구역을 구성하기 위한 추가 기억공간이 필요
- 파일이 정렬되어 있어야 하므로 추가, 삭제가 많으면 효율이 떨어짐
- 색인을 이용한 액세스를 하기 때문에 액세스 시간이 랜덤 편성 파일보다 느림
- 장점
474. VSAM 파일
- 동적 인덱스 방법을 이용한 색인 순차 파일
- 정적 인덱스 : 데이터 파일 또는 레코드가 삽입되어도 인덱스의 구조가 변하지 않는 인덱스 방법
- 동적 인덱스 : 인덱스 파일 또는 데이터 파일을 블록으로 구성하고 블록은 추가적인 삽입 레코드를 감안하여 빈 공간을 준비해 둔 인덱스 방법
- 데이터 레코드가 저장되는 부분인 제어 구간, 몇 개의 제어 구간을 모아 놓은 제어 구역, 제어 구역에 대한 인덱스를 저장한 순차 세트, 순차 세트의 상위 인덱스로 구성
- 레코드를 삭제 시 그 공간을 재사용함
478. 데이터 검증 방법
- 추출 검증
- 현행 시스템에서 최초 원시 데이터에 대한 검증을 수행
- 제공되는 원천 시스템 데이터에 대한 정합성 확인
- 전송 검증
- 전송된 추출 파일의 코드 전환 후 검증
- 데이터 전송 시 데이터 유실을 확인
- 전환 검증
- Tool을 이용해서 데이터를 추출하여 Staging DB를 구성한 후 검증
- 원천 시스템에서 작성된 검증 보고서와 Staging DB 적재 건수, 금액을 검증
- 적재 검증
- 목적 테이블 To-Be 에 대해 데이터를 검증
- 목적 테이블의 데이터 검증을 통해 오류 및 데이터 누락, 손실 등 확인
- 통합 검증
- 매핑 후 검증 (타켓 SAM 파일 또는 타켓 테이블)을 의미
- 오류 데이터를 분석하여 사전 정비 또는 전환 규칙 오류를 수정 반영
479. 데이터 정제 항목의 단계
- 전환 테스트 전
- 정의된 기준에 의하여 전환 제외 대상 데이터의 삭제
- 데이터 상호 간의 정합성이 유지될 수 있도록 데이터 보완
- 사용하는 데이터의 경우 매핑 수행
- 사용하지 않을 경우에는 해당 테이블 삭제
- 손실된 데이터를 정당한 값으로 복원
- 정당한 타입의 데이터로 수정
- 오류 데이터를 정당한 데이터로 변경 불필요한 데이터를 삭제 또는 초기화
- 전환 테스트 중
- 사전에 업무 규칙을 적용하여 정의한 정당한 데이터 값으로 정비
- 동일한 타입으로 전환
- 1단계 정제 대상 항목의 정제 내용과 동일하게 정제
- 전환 테스트 후
- 매핑 정의서에 작성된 전환 규칙을 이용하여 전환 프로그램에 해당 내용을 추가하여 프로그램 수행 시 정제
481. SELECT
- 테이블에 저장된 데이터 중 특정 컬럼을 조회하고자 할 때는 해당 컬럼 이름을 SELECT 절 뒤에 기술
- 테이블에 저장된 모든 컬럼의 데이터를 검색하고자 할 때는 컬럼명 없이 아스테리스크(*) 기호를 이용
- 출력 결과
- SELECT 명령을 통해 검색한 결과는 중복이 포함된 상태로 출력
- DISTINCT 키워드를 SELECT 뒤, 컬럼명 앞에 기술하여 검색한 결과는 중복을 제거한 결과를 출력

482. 집합연산자
- 집합연산 : 테이블을 집합 개념으로 보고, 두 테이블 연산에 집합 연산자를 사용하는 방식
- 집합 연산자의 유형
- UNION : 여러 SQL문의 결과에 대한 합집합, 중복 행 제거
- UNION ALL : 여러 SQL문의 결과에 대한 합집합, 중복행 제거하지 않음
- INTERSECT : 여러 SQL문의 결과에 대한 교집합, 중복행 제거
- EXCEPT (MINUS) : 앞의 SQL문의 결과와 뒤의 SQL문의 결과 사이의 차집합, 중복행 제거, 일부 제품의 경우 MINUS 사용
483. SELECT
- SELECT * FROM 학생 WHERE 이름 = '김철수' ; : 김철수에 대한 전체 컬럼을 조회한 결과
- SELECT * FROM 학생 WHERE 점수 = 'A' ; : 점수 A를 받은 학생들의 전체 컬럼을 조회한 결과
- SELECT 이름, 과목, 점수 FROM 학생 WHERE 이름 = '김철수' ; : 학생 Table을 조회한 결과는 문제의 결과와 같이 김철수 학생에 대한 이름, 과목, 점수에 대한 결과값
- SELECT 이름, 과목, 점수 FROM 학생 WHERE 점수 = 'A' ; : 점수 A를 받은 학생들의 전체 컬럼을 조회한 결과
487. 외부 조인
- 왼쪽 외부 조인 LEFT OUTER JOIN
- 왼쪽 테이블의 모든 데이터와 오른쪽 테이블의 동일 데이터를 추출
- 예시
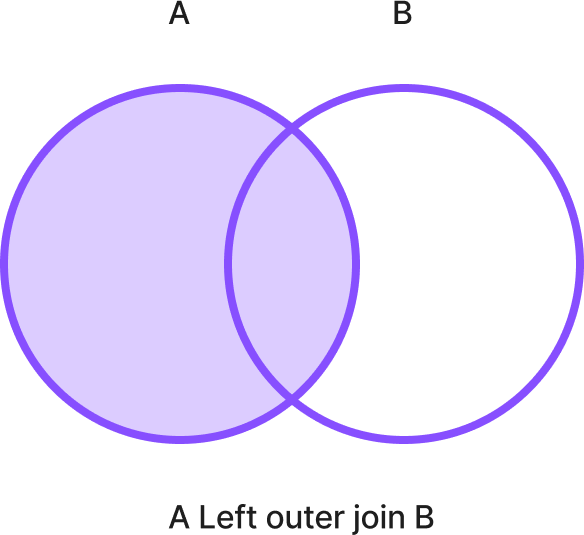
-
SQL 결과 Select A.이름, A.나이, B.취미
From A Left Outer Join B
On A.이름 = B.이름김철수, 10, 축구
김영희, 20, Null
- 오른쪽 외부 조인 RIGHT OUTER JOIN
- 오른쪽 테이블의 모든 데이터와 왼쪽 테이블의 동일 데이터를 추출
- 예시

-
SQL 결과 Select A.이름, A.나이, B.취미
From A Right Outer Join B
On A.이름 = B.이름김철수, 10, 축구
차길동, Null, 야구
- 완전 외부 조인 FULL OUTER JOIN
- 양쪽의 모든 데이터를 추출
- 예시

-
SQL 결과 Select A.이름, A.나이, B.취미
From A Full Outer Join B
On A.이름 = B.이름김철수, 10, 축구
김영희, 20, Null
차길동, Null, 야구
489. 권한 허가
- GRANT 명령문을 사용 : WITH GRANT OPTION를 이용하여 부여받은 권한을 다른 사용자에게 허가가 가능
- 예시
-
GRANT 권한 [컬럼 리스트] ON 객체 TO {사용자 | 역할 | PUBLIC}
[ WITH GRANT OPTION ]; - CUST 테이블에 갱신(UPDATE) 권한을 부여받은 사용자 USER01을 WITH GRANT OPTION 기능에 의해 CUST 테이블을 사용자 USER02에게 권한 부여가 가능
- WITH GRANT OPTION를 이용하여 부여받은 객체에 권한은 REVOKE 명령문을 사용하여 권한 회수 시 다른 사용자에게 허가했던 권한들도 연쇄적으로 취소되며 기본적으로 권한을 허가했던 사람만 그 권한을 취소 할 수 있음
-
492. 역할
- Role : 사용자에게 허가할 수 있는 연관된 권한들의 그룹
- 각 사용자는 여러 역할에 속할 수도 있으며 여러 사용자가 같은 역할을 가질 수 있음
- 예시
- 역할 사용 전
-
GRANT CREATE TABLE, ALTER TABLE, DROP TABLE TO USER01;
GRANT CREATE TABLE, ALTER TABLE, DROP TABLE TO USER02;
GRANT CREATE TABLE, ALTER TABLE, DROP TABLE TO USER03;
REVOKE DROP TABLE FROM USER01;
REVOKE DROP TABLE FROM USER02;
REVOKE DROP TABLE FROM USER03;
-
- 역할 사용 후
-
사용자들에게 부여하고자 하는 CREATE TABLE, DROP TABLE를 PROGRAMMER에 부여하여 동일한 권한을 사용자들에게 부여
CREATE ROLE PROGRAMMER; //역할 PROGRAMMER 생성
GRANT CREATE TABLE, ALTER TABLE, DROP TABLE TO PROGRAMMER;
GRANT PROGRAMMER TO USER01; //사용자 USER01에게 PROGRAMMER RNJSGKS QNDU
GRANT PROGRAMMER TO USER02;
GRANT PROGRAMMER TO USER03;
REVOKE DROP TABLE FROM PROGRAMMER;
//역할의 PROGRAMMER에서 DROP TABLE 권한을 회수하면 PROGRAMMER 권한을 부여받았던 모든 사용자에게서 DROP TABLE 권한이 회수
-
- 역할 사용 전
498. 릴레이션의 카디널리티와 차수
- 차수 Degree : 속성의 수
- 카디널리티 Cardinality : 튜플(향)의 수

499. 병행제어 기법
- 로킹 Locking
- 데이터베이스 관리에서 하나의 트랜잭션에 사용되는 데이터를 다른 트랜잭션이 접근하지 못하게 하는 것을 의미
- 트랜잭션들은 갱신할 때는 반드시 로킹 → 실행 → 해제의 규칙을 따라 실행
- 검증 기법 Validation
- 트랜잭션 처리 시 먼저 메모리상에서 복사본에 대한 연산을 수행하고 검증 완료 시 DBMS에 반영하는 기법
- 읽기 Read 단계는 메모리상에서 데이터 연산 수행
- 검증 Validation 단계는 트랜잭션의 직렬성 확인 단계
- 쓰기 Write 단계는 검증 성공 시 DBMS에 반영하고, 검증 실패 시 철회 Rollback하는 단계
- 타임 스탬프 기법 Timestamp Ordering
- 트랜잭션 순서 규칙은 시스템 계수기, 논리적 계수기를 이용하여 해당 트랜잭션의 도착 시간 별로 타임스탬프를 할당하는 기법 : 트랜잭션이 시스템 들어오는 순서대로 고유값 부여
- 직렬화 기법으로 트랜잭션 간의 순서를 미리 정하는 방법
500. 카티션 프로덕트
- 조인 조건 : 두 테이블 사이에 속하는 컬럼 값들을 비교 연산자로 연결한 형태
- 조인 조건을 생략한 경우 또는 조인 조건을 잘못 작성하게 되면 카티션 프로덕트(Cartesian Product, Cross Join) 연산이 수행되어 원하지 않은 결과를 얻게 됨
- 예시
| R1 | 학번 | R2 | 이름 | 카티션 프로덕트 수행 결과 | 학번 | 이름 |
| 1000 | 홍길동 | 1000 | 홍길동 | |||
| 2000 | 이순신 | 1000 | 이순신 | |||
| 2000 | 홍길동 | |||||
| 2000 | 이순신 |
'자격증 > 정보처리기사' 카테고리의 다른 글
| [정보처리기사 실기] 정보처리기사 2020년 1회 실기문제 (0) | 2025.03.14 |
|---|---|
| [정보처리기사 필기] 기출문제 - 501 ~ 550. 오답노트 (0) | 2025.03.13 |
| [정보처리기사 필기] 기출문제 - 401 ~ 450. 오답노트 (2) | 2025.03.11 |
| [정보처리기사 필기] 기출문제 - 351 ~ 400. 오답노트 (0) | 2025.03.10 |
| [정보처리기사 필기] 기출문제 - 301 ~ 350. 오답노트 (1) | 2025.03.07 |