


403. 절차형 SQL 유형의 프로시저, 트리거, 사용자 정의 함수
- 트리거
- 데이터베이스에 특정한 변경이 가해졌을 때 (명시된 이벤트가 발생할 때마다) DBMS가 이에 대응해서 자동적으로 호출하는 일종의 프로시저
- 트리거의 실행 : 트리거링 사건에 의해 내부적으로 이루어지며 트리거를 이벤트(사건)-조건-동작(ECA) 규칙으로 실행
- 프로시저
- 사용자의 호출 명령에 의해 실행
- 사용자 정의 함수
- 사용자의 호출 명령에 의해 실행
- RETRUN 값을 반드시 명시해야 함
404. 관계 모델 / 관계 데이터 모델의 구성
- 관계 모델
- E.F CODE 박사가 1972년 제안한 데이터 모델
- 오늘날 대부분의 데이터베이스 관리시스템에서 지원하는 데이터 모델
- 실세계 데이터를 행과 열로 된 표(테이블, 릴레이션) 형태로 저장
- 한 테이블의 필드값을 이용하여 다른 테이블에 관련된 데이터를 찾는 식으로 검색하는 데이터 모델
- 관계 데이터 모델의 구성
- 데이터 베이스의 테이블들의 집합(모임)으로 표현
- 테이블 : 튜플 (행, 레코드)들의 집합으로 표현
- 튜플 : 애트리뷰트 (컬럼, 필드, 속성)들로 구성
| 요소 | 설명 |
| 속성 Attributes | 개체의 성질, 분류, 식별, 수량, 상태 등을 나타내는 세부 정보의 관리 요소로서 개체를 구성하는 항목 |
| 튜플 Tuple | •릴레이션의 행을 구성하는 속성 값들의 집합 •행(row), 레코드(record)와 같은 개념 |
| 차수 Degree | 속성들의 수 |
| 카디날리티 Cardinality | 튜플들의 수 |
| 도메인 Domain | •하나의 속성이 취할 수 있는 같은 타입의 원자 값들의 집합 •표현되는 속성 값의 범위를 나타냄 |
| 릴레이션 인스턴스 Relation Instance | •릴레이션의 어느 시점에 들어있는 튜플(행)들의 집합 (동적인 성질) •튜플(행)들의 집합으로 현재 들어가 있는 실제 데이터를 지칭 |
406. 릴레이션의 Degree와 Cardinality
- 차수 Degree : 속성의 수
- 카디널리티 Cardinality : 튜플(향)의 수
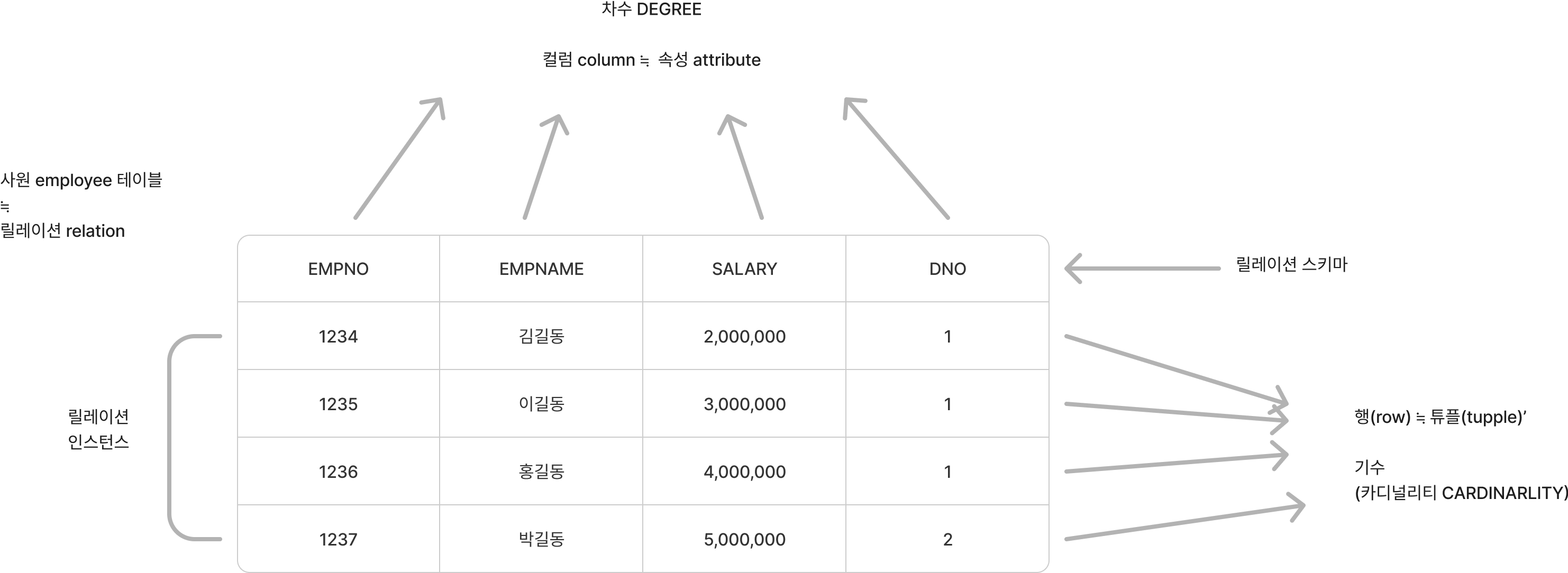
407. 데이터베이스의 키
- 데이터베이스에서 조건에 만족하는 튜플을 찾거나 순서대로 정렬할 때 튜플들을 서로 구분할 수 있는 기준이 되는 속성들
- 데이터베이스 키의 특징
- 유일성 Uniqueness
- 하나의 키 값으로 하나의 튜플만을 유일하게 식별할 수 있어야 함
- 기본키 primary key, 후보키 candiate key, 슈퍼키 super key
- 최소성 Minimality
- 속성의 집합인 키가 릴레이션의 모든 튜플을 유일하게 식별하기 위해 꼭 필요한 속성들로 구성된 것을 의미
- 기본키 primary key, 후보키 candiate key
- 유일성 Uniqueness
- 데이터베이스 키의 종류
- 후보키 candidate key
- 릴레이션을 구성하는 속성들 중에서 튜플을 유일하게 식별할 수 있는 하나 또는 몇 개의 속성 집합
- 유일성과 최소성을 모두 만족
- 기본키 primary key
- 릴레이션의 유일한 식별자 (유일성, 최소성 모두 만족)
- 기본키로 지정된 속성은 같은 값을 갖지 못함
- 후보키 중에서 선정된 키로 중복값을 가질 수 없음
- Not null, Unique, 외래키 foreign key로 참조될 수 있음
- 대체키 alternate key
- 후보키가 둘 이상 되는 경우에 기본키로 선택되지 못한 후보키들
- 후보키 = 기본키 + 대체키
- 슈퍼키 super key
- 유일성만 있고 최소성이 없는 속성의 집합
- 외래키 foreign key
- 한 테이블의 키 중 다른 테이블의 튜플을 식별할 수 있는 키
- 후보키 candidate key
408. 데이터 무결성
- 데이터 무결성 강화 : 데이터베이스에 저장된 데이터의 일관성과 정확성을 지키는 것을 말하며, 데이터가 무결성을 가지도록 하는 행위
- 데이터 무결성 종류
| 종류 | 설명 | 제약조건 |
| 엔티티(개체) 무결성 Entity Integrity |
• 기본키는 반드시 값을 가짐 - NULL 허용 안함 •기본키는 유일성을 보장하는 최소한의 집합 |
Primary Key, NOT NULL |
| 참조 무결성 Referential Integrity |
•외래키 속성은 참조할 수 없는 값을 지닐 수 없음 •외래키 값은 그 외래키가 기본키로 사용된 릴레이션의 기본키 값이거나 NULL 값일 것 |
Foreign Key |
| 속성 무결성 Attribute Integrity |
컬럼은 지정된 데이터 형식을 반드시 만족하는 값만 포함 | Character, Date, LONG, VARCHAR2, NUMBER |
| 키 무결성 Key Integrity |
한 릴레이션에 같은 키 값을 가진 튜플들은 허용 안됨 | Primary Key + Unique Index |
| 사용자 정의 무결성 User Defined Integrity |
모든 데이터는 업무 규칙을 준수해야 함 | Trigger, User Define, Data Type, Check, DEFAULT Value |
| 도메인 무결성 Domain Integrity |
특정 속성 값이 미리 정의된 도메인 범위에 속해야 함 | CHECK, DEFAULT |
409. 참조 무결성
- 참조 무결성 유지를 위해 관계를 맺고 있는 릴레이션에서 참조 속성에 대한 DML를 수행 시 지켜야 하는 관계 규칙
| 규칙 | 세부내용 | 사례 |
| Restrict | 자식 Table에 참조하는 값이 미 존재 시 수정/삭제 허용 | 부서번호 10은 홍길동이 참조, 삭제 불가 |
| Cascade | 부모 Table PK, 자식 Table의 FK를 연쇄 삭제 | 부모테이블에서 기획부(10) 삭제 시 자식 테이블의 홍길동도 같이 삭제 |
| Default | 부모 Table 수정/삭제 허용, 자식 Table의 FK는 지정된 값으로 변경 | Default값이 '99'이면 부모 Table PK 삭제 시 자식 Table의 FK값을 '99'로 변경 |
| Customized | 특정 조건 만족 시 수정/삭제 허용 | 특정조건 : 계약기간 만료, 계약기간 만료 시 데이터 삭제 허용 |
| Null | 부모 Table PK 삭제 시 자식 Table FK를 Null | 부모 Table PK 삭제 후 자식 Table FK를 "Null" |
| No Effect | 조건없이 수정/삭제 허용 | 부모 Table PK 자유롭게 삭제 가능 |
- 테이블 제약 조건 설계
- 삭제 제약 조건 설계 Delete Constraint
- 참조된 기본키의 값이 삭제될 경우의 처리 내용을 정의
- Cascade : 참조한 테이블에 있는 외부키와 일치하는 모든 Row가 삭제
- Restricted : 참조한 테이블에 있는 외부키에 없는 것만 삭제 가능
- Nullify : 참조한 테이블에 정의된 외부키와 일치하는 것을 Null로 수정
- 수정 제약 조건 설계 Update Constraint
- 참조된 기본키의 값이 수정될 경우의 처리 내용을 정의
- Cascade : 참조한 테이블에 있는 외부키와 일치하는 모든 Row가 수정
- Restricted : 참조한 테이블에 있는 외부키에 없는 것만 수정 가능
- Nullify : 참조한 테이블에 정의된 외부키와 일치하는 것을 Null로 수정
- 삭제 제약 조건 설계 Delete Constraint
410. 개체 무결성
- 엔티티 무결성
- 테이블의 모든 행들이 유일하게 식별되는 무결성
- 대부분의 경우 기본키에 의해 강화
- 기본키 : 반드시 값을 가짐(NULL 허용 안함), 유일성을 보장하는 최소한의 집합
- 제약조건 : Primary Key, NOT NULL

411. 제약조건
- 제약 조건 : 데이터베이스에 저장되는 데이터의 정호가성을 보장하기 위해 키를 이용하여 입력되는 데이터 제한을 주는 것
- 제약 조건의 종류
- 도메인 제약 조건
- 각 필드의 값은 반드시 그 필드의 도메인에 속하는 원자값
- 사례 : Student 테이블의 Gpa 필드의 값은 4.5 이내의 실수값
- 엔티티 제약 조건
- 테이블마다 튜플을 서로 구분할 수 있는 필드가 존재 -> 이 필드를 Primary key(기본키)라고 함
- 기본키 값은 널 값이 될 수 없다는 조건을 엔티티 무결성 제약 조건
- 사례 : Student 테이블에서 SSN 필드는 각 학생들을 구분하는 필드
- 참조 무결성 제약 조건
- 한 테이블의 필드값은 다른 테이블의 기본키 값을 참조할 때 두 테이블 사이에 참조 무결성 제약조건
- 사례 : Student 테이블의 dno 필드 값은 Department 테이블의 dnumber 필드값을 가져야 함. 이 때 Student 테이블의 dno 필드를 외래키 foreign key라고 함
- 도메인 제약 조건
- 데이터베이스 무결성 보장 방법 : 응용 프로그램, 트리거, 제약조건을 이용
416. 관계 데이터 언어
- 관계 데이터 언어
- 관계 데이터베이스의 릴레이션을 조작하기 위한 기본 연산에는 관계대수와 관계해석이 있음
- 사용자의 입장에서 볼 때 데이터를 처리하는 데이터 언어가 되며 관계대수는 절차적 언어, 관계해석은 비절차적 언어
- 관계 대수
- 관계형 데이터베이스에서 원하는 정보와 그 정보를 검색하기 위해서 어떻게 유도하는 가를 기술하는 절차적인 언어
- 릴레이션을 처리하기 위해 연산자와 연산규칙을 제공하는 언어
- 피연산자가 릴레이션이고 결과도 릴레이션
- 관계 해석
- 코드 E.F.Code 박사가 제안한 것
- 수학의 술어해석에 기반
- 원하는 정보가 무엇이라는 것만 정의하는 비절차적 특징을 갖고 있음
- SQL문과 같은 질의어를 사용
- 튜플 관계해석과 도메인 관계해석으로 구성되며 원하는 데이터만 명시하고 질의를 어떻게 수행할 것인가는 명시하지 않는 선언적인 언어
417. 관계 대수의 연산자
- 순수 관계 연산자 : 관계 데이터베이스에 적용할 수 있도록 특별히 개발한 관계 연산자
| 종류 | 연산자 기호 | 설명 |
| Select | 시그마 σ |
•릴레이션에 존재하는 튜플 중에서 선택 조건을 만족하는 튜플의 부분집합을 구하여 새로운 릴레이션 생성 •릴레이션의 행(가로)에 해당하는 튜플을 구하는 것(수평 연산) |
| Project | 파이 π |
•주어진 릴레이션에서 속성 리스트에 제시된 속성만 추출하는 연산 •릴레이션의 열(세로)에 해당하는 속성을 추출하는 것 (수직 연산자) |
| Join | ⋈ | 공통 속성을 중심으로 두 개의 릴레이션을 하나로 합쳐서 새로운 릴레이션을 만드는 연산 |
| Division | ÷ | X ⊃ Y 두 개의 릴레이션 R(X)와 S(Y)가 있을 때, R의 속성이 S의 속성값을 모두 가진 튜플에서 S가 가진 튜플에서 S가 가진 속성을 제외한 속성만을 구하는 연산 |
- 일반 집합 연산자
| 종류 | 유형 | 설명 |
| 합집합 UNION | ⋃ | 두 릴레이션에 존재하는 튜플의 합집합을 구하되, 결과로 생성된 릴레이션에서 중복되는 튜플 제거 |
| 교집합 INTERSECTION | ⋂ | 두 릴레이션에 존재하는 튜플의 교집합을 구하는 연산 |
| 차집합 DIFERENCE | – | 두 릴레이션에 존재하는 튜플의 차집합을 구하는 연산 |
| 교차곱 CARTESIAN PRODUCT | ⅹ | 두 릴레이션에 있는 튜플들의 순서쌍을 구하는 연산 |
418. 관계 대수의 순수관계 연산자
- 순수 관계 연산자 : 관계 데이터베이스에 적용할 수 있도록 특별히 개발한 관계 연산자
| 종류 | 연산자 기호 | 설명 |
| Select | 시그마 σ |
•릴레이션에 존재하는 튜플 중에서 선택 조건을 만족하는 튜플의 부분집합을 구하여 새로운 릴레이션 생성 •릴레이션의 행(가로)에 해당하는 튜플을 구하는 것(수평 연산) |
| Project | 파이 π |
•주어진 릴레이션에서 속성 리스트에 제시된 속성만 추출하는 연산 •릴레이션의 열(세로)에 해당하는 속성을 추출하는 것 (수직 연산자) |
| Join | ⋈ | 공통 속성을 중심으로 두 개의 릴레이션을 하나로 합쳐서 새로운 릴레이션을 만드는 연산 |
| Division | ÷ | X ⊃ Y 두 개의 릴레이션 R(X)와 S(Y)가 있을 때, R의 속성이 S의 속성값을 모두 가진 튜플에서 S가 가진 튜플에서 S가 가진 속성을 제외한 속성만을 구하는 연산 |
419. 관계 대수 중 일반집합 연산자
- 일반 집합 연산자
| 종류 | 유형 | 설명 |
| 합집합 UNION | ⋃ | 두 릴레이션에 존재하는 튜플의 합집합을 구하되, 결과로 생성된 릴레이션에서 중복되는 튜플 제거 |
| 교집합 INTERSECTION | ⋂ | 두 릴레이션에 존재하는 튜플의 교집합을 구하는 연산 |
| 차집합 DIFERENCE | – | 두 릴레이션에 존재하는 튜플의 차집합을 구하는 연산 |
| 교차곱 CARTESIAN PRODUCT | ⅹ | 두 릴레이션에 있는 튜플들의 순서쌍을 구하는 연산 |
421. 튜플 관계 해석식
- 튜플 관계 해석식의 일반적 형태의 풀이
- 튜플 관계 해석식의 일반적 형태 : {t1.A1, t2.A2, ..., tn.An | COND(t1, t2, ..., tn, tn+1, tn+2, ..., tn+m)}.
- t1, t2, ..., tn, tn+1, tn+2, ..., tn+m은 튜플 변수
- 각 Ai는 ti가 범위로하는 릴레이션의 애트리뷰트
- COND는 조건 또는 튜플 관계 해석의 식 formula
- 막대 |
- 막대 | 왼편 기술한 한정 애트리뷰트들 : 목표 리스트
- 막대 | 오른편 기술한 조건에 만족하는 튜플로부터 추출
- 튜플 변수
- 범위변수 range variable
- 지정된 릴레이션의 튜플을 하나씩 그 값으로 취할 수 있는 변수
- 튜플 변수가 특정 릴레이션의 튜플들을 하나씩 그 변수 값으로 취한다는 표현을 명시적으로 하기 위해서 범위식을 사용
- 한정 애트리뷰트
- 릴레이션 R에 대해 튜플 변수 t가 나타내는 튜플의 어떤 애트리뷰트 A의 값을 표현하기 위한 것
- t.A 또는 t[A]로 나타내며 아래의 튜플 해석식에서 한정 애트리뷰트는 a, 주문수량, a.주문액수, a.고객번호
423. 개념적 설계 단계
- 한 조직체에서 사용되는 정보 모델 구축
- 높은 추상화 수준의 데이터 모델을 사용
- 개체 타입, 관계 타입, 속성들을 식별하고, 속성들의 도메인을 결정, 후보키와 기본키를 결정
- 개념적 스키마 (ER 스키마)는 ER 다이어그램으로 표현
- 논리적 설계 단계의 앞 단계에서 수행
- 대표적인 데이터 모델 : ER 모델
426. 데이터 모델링
- 사용자 요구사항을 분석하고 필요한 데이터 요소를 도출하여 적절한 데이터 구조를 정의하는 데이터베이스 설계 과정의 핵심 기법
- 개념적 데이터 모델
- 숙련된 설계자는 모델링 과정에서 개체 타입과 속성, 식별자를 한 번에 도출할 수 있지만 일반적으로 개념 모델링을 수행
- 업무의 관심 대상이 되는 정보를 갖고 있거나, 그에 대한 정보를 관리할 필요가 있는 유형, 무형의 사물(개체)을 의미
- 현실 세계를 관찰하여 컴퓨터로 관리해야 할 정보, 혹은 데이터를 개체 타입 또는 관계 타입으로 도출

429. 함수 종속성의 유형
- 완전 함수종속

- 일반속성이 식별자 전부에 종속
- 부분 함수종속

- 일반속성이 식별자 일부에 종속
- 제 2정규화 필요
- 이행 함수종속

- 일반속성 간 함수적 종속
- 제 3정규화 필요
- 결정자 함수종속
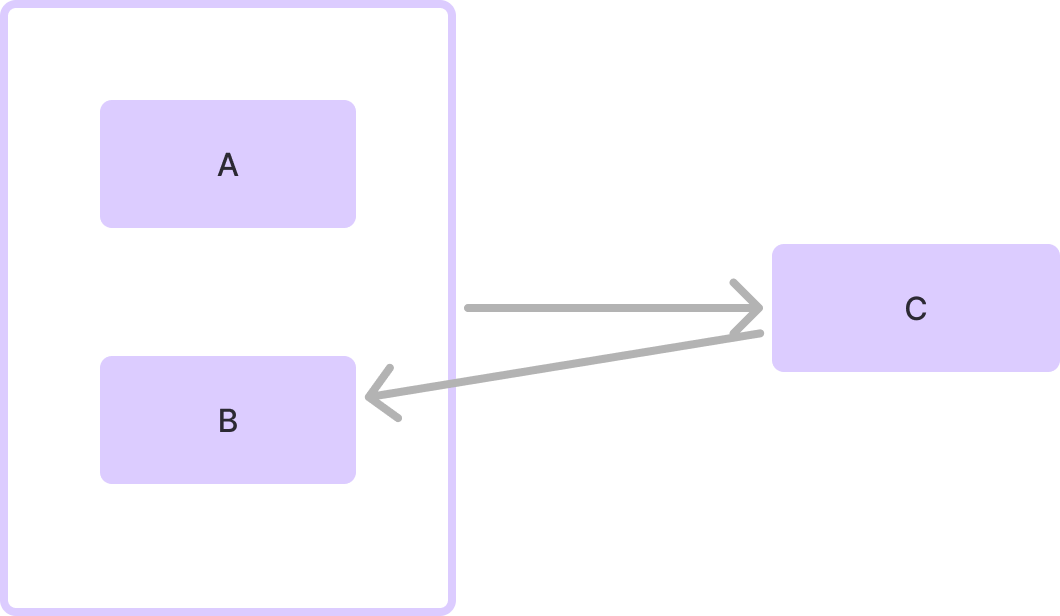
- 결정자가 후보키가 아닌 경우 존재, 후보키에 종속자 존재
- BCNF 정규화 필요
431. 정규화
- 관계형 데이터베이스 설계 시 중복을 최소화하도록 데이터를 구조화하는 프로세스
- 제대로 조직되지 않은 테이블들과 관계들을 작고 잘 조직된 테이블과 관계들로 나누는 무손실 분해를 포함
- 정규화를 수행하는 목적
- 하나의 테이블에서의 데이터의 삽입, 삭제, 변경이 정의된 관계들로 인하여 데이터베이스의 나머지 부분들로 전파되게 하는 것
- 어떤 관계라도 데이터베이스 내에서 표현이 가능하도록 만드는 것
- 관계에서 바람직하지 않은 삽입, 삭제, 갱신 이상이 발생하지 않도록 하는 것
- 새로운 형태의 데이터가 삽입될 때 관계를 재구성 할 필요성을 줄임
- 보다 간단한 관계 연산에 기초하여 검색을 보다 효율적으로 함
- 정규화의 원칙 : 낮은 차수의 정규화를 만족한 상태로 높은 차수의 정규화를 진행
- 무손실 표현 : 같은 의미의 정보를 유지하면서 더 바람직한 구조를 만듬
- 자료의 중복성 감소 : 중복되는 정보는 삭제하거나 통합
- 분리의 원칙 : 독립적인 관계는 별개의 릴레이션으로 표현, 릴레이션 각각에 대해 독립적 조작이 가능
436. 분산 데이터베이스
- 하나의 데이터베이스 관리 시스템 DBMS이 여러 CPU에 연결된 저장장치들을 제어하는 형태의 데이터베이스
- 분산 데이터베이스의 투명성
- 분할 투명성 (단편화) : 하나의 논리적 릴레이션이 여러 단편으로 분할되어 각 단편의 사본이 여러 사이트에 저장
- 위치 투명성 : 사용하려는 데이터의 저장 장소 명시 불필요, 위치정보가 시스템 카탈로그에 유지되어야 함
- 지역사상 투명성 : 지역 DBMS와 물리적 DB사이의 매핑 보장, 각 지역 시스템 이름과 무관한 이름 사용 가능
- 중복 투명성 : DB 객체가 여러 site에 중복되어 있는지 알 필요가 없는 성질
- 장애 투명성 : 구성요소(DBMS, Computer)의 장애에 무관한 트랜잭션의 원자성 유지
- 병행 투명성 : 다수 트랜잭션 동시 수행 시 결과의 일관성 유지, Time Stamp, 분산 2단계 Locking을 이용 구현
437. 분산 데이터베이스의 장단점
- 장점
- 지역 자치성, 점증적 시스템 용량 확장
- 신뢰성, 가용성
- 효용성, 융통성
- 빠른 응답 속도와 통신비용 절감
- 데이터의 가용성과 신뢰성 증가
- 시스템 규모의 적절한 조절
- 각 지역 사용자의 요구 수용 증대
- 단점
- 소프트웨어 개발 비용
- 오류의 잠재성 증대
- 처리 비용의 증대
- 설계, 관리의 복잡성과 비용
- 불규칙한 응답 속도
- 통제의 어려움
- 데이터 무결성에 대한 위협
439. 데이터베이스 암호화
- 외부로부터의 공격, 내부자의 불법행위로 인한 데이터 유출을 방지하기 위해 DB내에 저장된 데이터를 해독 불가능한 형식의 암호문으로 저장하는 행위
- 데이터베이스 암호화 유형
- 디스크 전체 Storage Level 암호화
- DB 파일을 보호하고 비인가 사용자에 의한 불법적인 파일 열람을 제한
- 인가된 서버만이 정상적인 암호화된 데이터를 해독하고 열람이 가능
- 컬럼 Column Level 암호화
- 개인정보, 기업의 민감한 정보를 담고 있는 특정 테이블의 컬럼만을 암호화
- DB 서버에 접속하는 사용자들을 구분하고 정의된 암/복호화 정책에 따라 데이터를 제공
- 컬럼 암호화의 종류
- Plug - In 방식 : DB 서버 내의 플러그인을 장착하여 암복호화를 수행하는 방식
- API 호출방식 : 애플리케이션 서버가 암복호화를 위한 API을 호출하여 수행하는 방식
- 디스크 전체 Storage Level 암호화
440. 하둡 Hadoop
- 대량의 자료를 처리할 수 있는 큰 컴퓨터 클러스터에서 동작하는 분산 응용 프로그램을 지원하는 프리웨어 자바 소프트웨어 오픈 소스 프레임워크
- 가상화 기술을 이용하여 여러 개의 저렴한 컴퓨터를 마치 하나인 것처럼 묶어 대용량 데이터를 처리하는 기술
- 수천대의 분산된 x86 장비에 대용량 파일을 저장할 수 있는 기능을 제공하는 분산파일 시스템
- 저장된 파일 데이터를 분산된 서버의 CPU와 메모리 자원을 이용해 쉽고 빠르게 분석할 수 있는 컴퓨팅 플랫폼인 맵리듀스로 구성됨
443. 데이터베이스 이중화
- 물리적으로 떨어져 이쓴ㄴ 여러 개의 데이터베이스에 대하여 로컬 데이터베이스의 변경된 내용을 원격데이터베이스에 복제하고 관리하는 것
- 데이터베이스 이중화의 목적 : 데이터베이스의 무정지 서비스
- 데이터베이스 이중화 유형
- Active - Active
- 클러스터를 구성하는 컴포넌트를 동시에 가동하는 구성
- 시스템 다운 시간이 짧고, 전환성능이 빠름
- Active - Stand
- 클러스터를 구성하는 컴포넌트 중 실제 가동하는 것은 Active, 남은 것은 Standby(대기)로 구성
- Cold - Standby : 평소 Standby 서버 다운 / Hot - Standby : 평소 Standby 서버 기동
- 세부 종류 : Fail-over 소요시간 - Hot < Warm < Cold
- Hot Standby : Standby 쪽 장비 기동 후 즉시 사용이 가능, Fail-over 소요시간은 필요
- Warm Standby : Standby 쪽 장비 기동 후 이용하기 위하여 어느 정도 설정 및 준비 필요
- Cold Standby : Standby 측을 평소 정지 시켜두며 필요에 따라 직접 켜서 구성
- Active - Active
445. 파티셔닝의 장단점
- 장점
- 가용성 : 물리적인 파티셔닝으로 인해 전체 데이터의 훼손 가능성이 줄어들고 데이터 가용성 향상
- 관리용이성 : 큰 Table을 제거하여 관리가 쉬움
- 성능 : 특정 DML과 Query의 성능 향상, 주로 대용량 Data Write 환경에서 효율적, 많은 Insert가 있는 OLTP 시스템에서 Insert 작업들을 분리된 파티션들로 분산시켜 경합을 줄임
- 단점
- 테이블 간의 조인에 대한 비용이 증가
- 테이블과 인덱스를 별도로 파티션 작업은 불가, 테이블과 인덱스를 함께 파티셔닝이 가능
447. 파티셔닝의 방법
- Horizontal Partitioning
- 데이터의 개수를 기준으로 나누어 파티셔닝
- 데이터의 개수가 작아지면서 인덱스의 개수도 작아지며 성능도 향상
- 서버간의 연결 과정이 많아짐
- 데이터를 찾는 과정이 기존보다 복잡하기 때문에 Latency가 증가
- 하나의 서버가 고장나게 되면 데이터의 무결성이 깨질 수 있음
- Vertical Partitioning
- 테이블의 컬럼을 기준으로 나누어 파티셔닝
- 정규화하는 과정도 이와 비슷하다고 볼 수 있지만 Vertical Partitioning은 이미 정규화된 Data를 분리하는 과정
- 자주 사용하는 컬럼 등을 분리시켜 성능을 향상
448. 클러스터
- 어떤 정해진 컬럼 값을 기준으로 동일한 값을 가진 하나 이상의 테이블의 로우를 같은 장소에 저장하는 물리적인 기법
- 디스크로부터 데이터를 읽어오는 시간을 줄이기 위해서 조인이나 자주 사용되는 테이블의 데이터를 디스크의 같은 위치에 저장시키는 방법
- 클러스터의 장점
- 그룹된 컬럼 데이터 행들이 같은 데이터 Block에 저장되기 때문에 디스크 I/O를 줄여줌
- 클러스터된 테이블 사이에 조인이 발생할 경우 그 처리 시간이 단축
- 클러스터 키 열을 공유하여 한번만 저장하므로 저장 영역의 사용을 줄여줌
- 데이터 조회 성능을 향상시킴
- 클러스터의 단점
- 데이터 저장, 수정, 삭제 또는 한 테이블 전체 Scan의 성능을 감소시킴
- 클러스터의 특징
- 클러스터 하기 좋은 테이블
- 주로 조회가 자주 발생하고 수정이 거의 발생하지 않는 테이블
- 컬럼 안의 많은 중복 데이터를 가지는 테이블
- 자주 조인되는 테이블
- 클러스터 키가 되기 좋은 컬럼
- 데이터 값의 범위가 큰 컬럼
- 테이블 간의 조인에 사용되는 컬럼
- 클러스터 키가 되기 나쁜 컬럼
- 특정 데이터 값이 적은 컬럼
- 자주 데이터 수정이 발생하는 컬럼
- LONG, LONG RAW 컬럼은 포함할 수 없음
- 클러스터 하기 좋은 테이블
'자격증 > 정보처리기사' 카테고리의 다른 글
| [정보처리기사 필기] 기출문제 - 501 ~ 550. 오답노트 (0) | 2025.03.13 |
|---|---|
| [정보처리기사 필기] 기출문제 - 451 ~ 500. 오답노트 (0) | 2025.03.12 |
| [정보처리기사 필기] 기출문제 - 351 ~ 400. 오답노트 (0) | 2025.03.10 |
| [정보처리기사 필기] 기출문제 - 301 ~ 350. 오답노트 (1) | 2025.03.07 |
| [정보처리기사 필기] 기출문제 - 251 ~ 300. 오답노트 (0) | 2025.03.06 |